マイクロサービス・セキュリティ・チートシート
はじめに
マイクロサービス・アーキテクチャは、クラウドベースおよびオンプレミスのインフラストラクチャ、ならびに大規模アプリケーションやサービスにおけるアプリケーション・システムの設計・実装において、ますます利用されています。アプリケーションの設計および実装の段階で対処すべき多くのセキュリティ上の課題があります。設計段階で取り組むべき基本的なセキュリティ要件は、認証と認可です。したがって、アプリケーション・セキュリティ・アーキテクトが、マイクロサービスベースのシステムにおいて認証と認可を実装するために、既存のアーキテクチャ・パターンを理解し適切に用いることが不可欠です。本チートシートの目的は、そのようなパターンを特定し、それらの活用方法についてアプリケーション・セキュリティ・アーキテクトへ推奨を行うことにあります。
エッジ層での認可
単純なシナリオでは、認可はエッジ層(APIゲートウェイ)でのみ行うことができます。APIゲートウェイは、下流のすべてのマイクロサービスに対する認可の適用を集中化するために活用でき、各サービス個別に認証とアクセス制御を提供する必要を排除できます。このようなケースでは、NIST は、内部サービスへの直接かつ匿名の接続(API ゲートウェイのバイパス)を防ぐために、相互認証などの緩和策を実装することを推奨しています。なお、エッジ層での認可には以下の制限があることに注意が必要です。
- すべての認可判断を API ゲートウェイに押し込むと、多数のロールやアクセス制御ルールを持つ複雑なエコシステムでは、管理が急速に困難になります。
- API ゲートウェイが「多層防御(defense in depth)」の原則に反する単一の意思決定点になり得ます。
- 運用チームが通常 API ゲートウェイを所有するため、開発チームは認可の変更を直接行えず、追加のコミュニケーションやプロセスのオーバーヘッドにより速度が低下します。
多くの場合、開発チームはエッジ層(粗い粒度)とサービス層の両方で認可を実装します。外部エンティティを認証するために、エッジは HTTP ヘッダー(例:「Cookie」や「Authorization」)で送信されるアクセストークン(参照トークンまたは自己完結型トークン)を使用するか、mTLS を使用できます。
サービス層での認可
サービス層での認可は、各マイクロサービスにアクセス制御ポリシーを適用するより強いコントロールを与えます。以降の議論では、NIST SP 800-162に従った用語と定義を使用します。アクセス制御システムの機能コンポーネントは、次のように分類できます。
- ポリシー管理ポイント(PAP):アクセス制御ルールの作成、管理、テスト、デバッグのためのユーザーインターフェイスを提供する。
- ポリシー決定ポイント(PDP):該当するアクセス制御ポリシーを評価してアクセス判断を算出する。
- ポリシー適用ポイント(PEP):保護対象オブジェクトへのアクセスを要求する主体からのリクエストに応じて、ポリシー判断を適用する。
- ポリシー情報ポイント(PIP):属性や、PDP が判断を行うために必要な情報を提供するための、ポリシー評価に必要なデータの取得元として機能する。
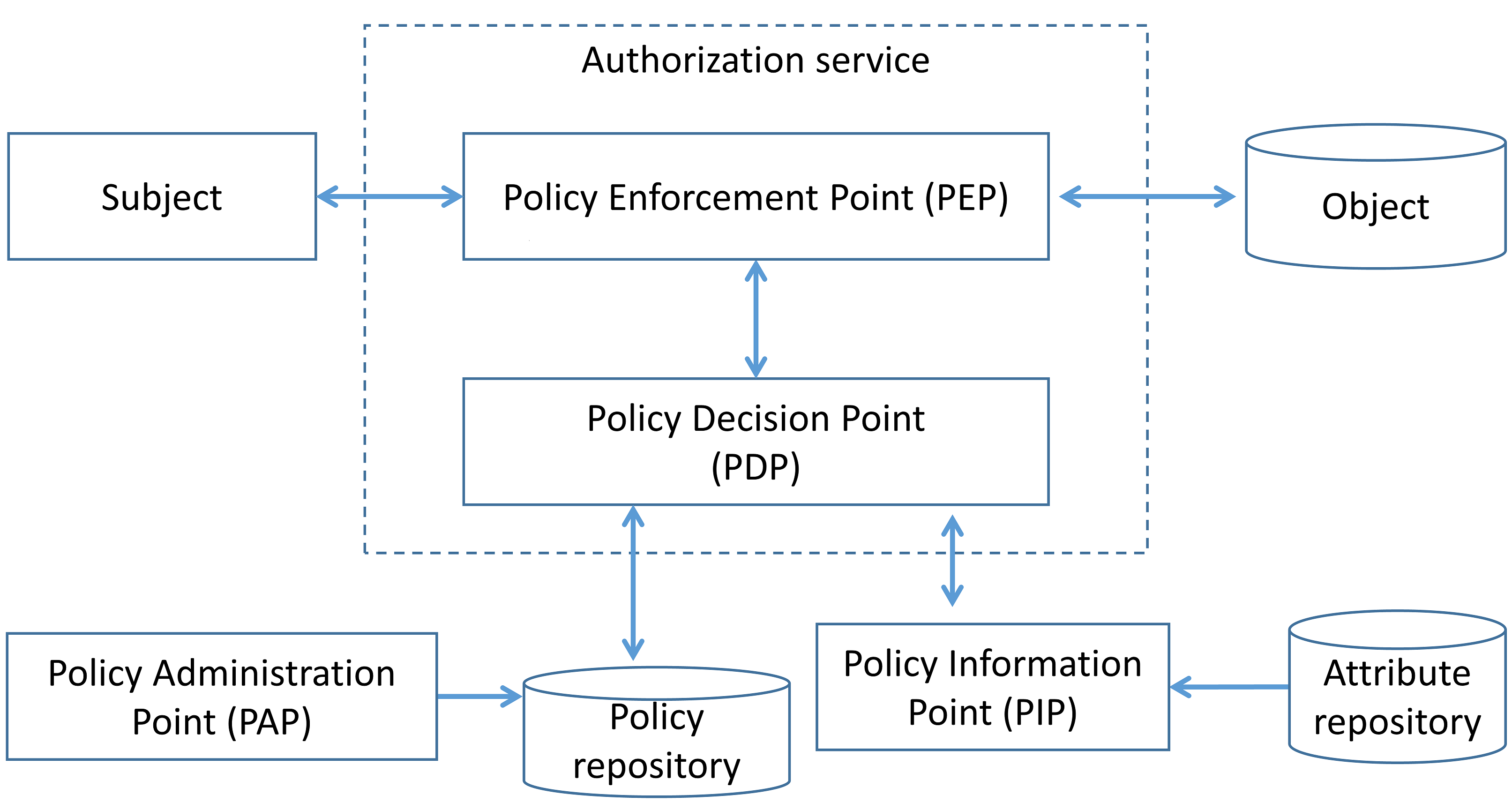
サービス層での認可:既存のパターン
分散型パターン
開発チームは、PDP と PEP
をマイクロサービスのコードレベルで直接実装します。必要なすべてのアクセス制御ルールと、そのルールの実装に必要な属性は、各マイクロサービス上で定義・保存されます(手順1)。マイクロサービスが、あるリクエスト(例えば、エンドユーザーのコンテキストや要求されたリソース
ID
などの認可メタデータを伴う)を受け取ると、マイクロサービスはそれを解析し(手順3)、アクセス制御ポリシーの判断を生成し、その後認可を適用します(手順4)。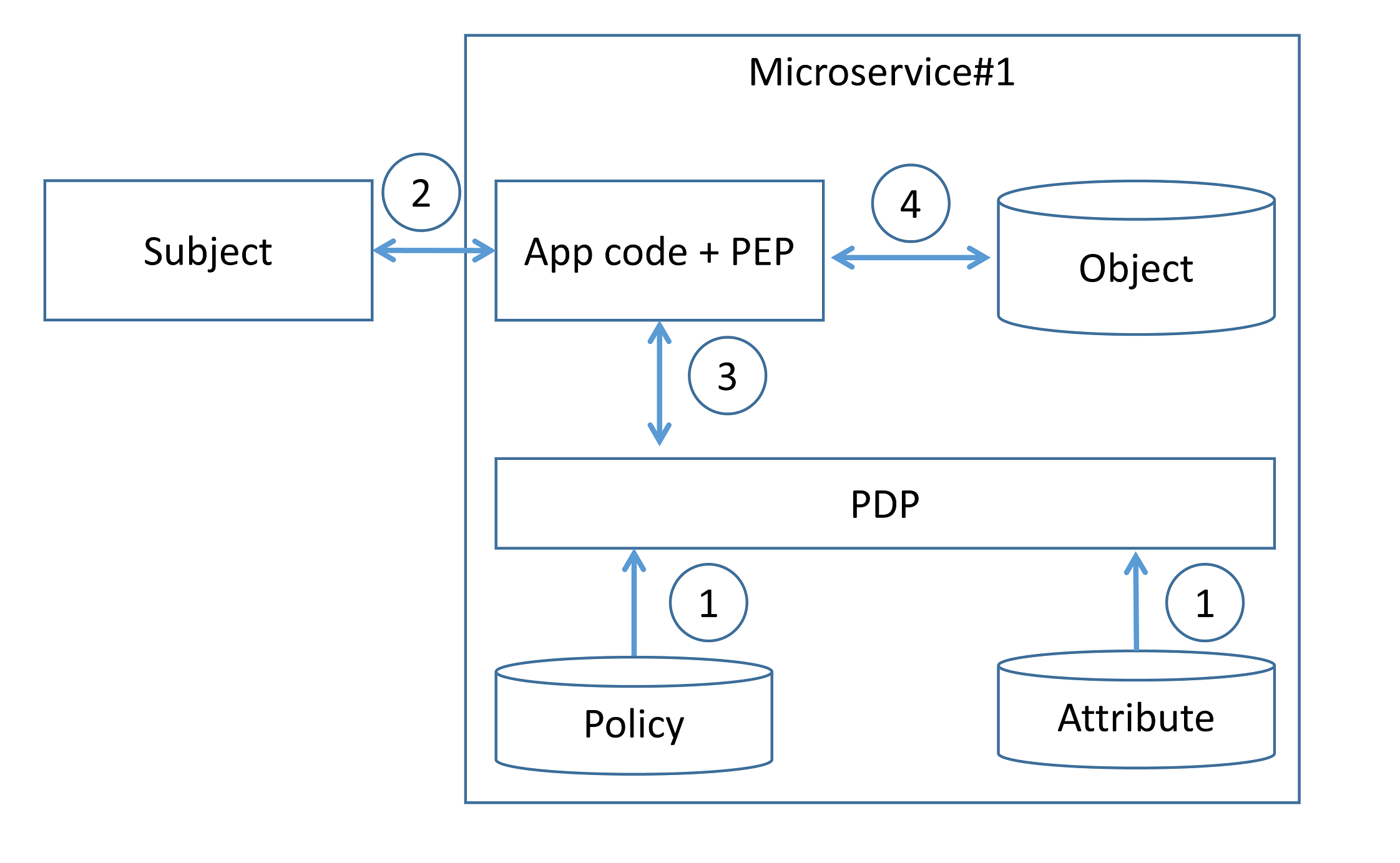
既存のプログラミング言語フレームワークは、開発チームがマイクロサービス層で認可を実装できるようにしています。たとえば、Spring Security は、(受信した JWT から抽出したスコープなどを用いて)リソースサーバにおけるスコープ検査を有効にし、それを認可の適用に利用することを開発者に許可します。
ソースコードレベルで認可を実装するということは、開発チームが認可ロジックを変更したい場合にはコードを更新しなければならないことを意味します。
単一のポリシー決定ポイントを用いた集中型パターン
このパターンでは、アクセス制御ルールは集中管理され、定義・保存・評価が行われます。アクセス制御ルールは PAP を用いて定義され(手順1)、それらのルールの評価に必要な属性とともに集中管理された PDP に届けられます(手順2)。主体がマイクロサービスのエンドポイントを呼び出すと(手順3)、マイクロサービスのコードはネットワーク呼び出しにより集中型の PDP を呼び出し、PDP はクエリ入力をアクセス制御ルールと属性に対して評価することでアクセス制御ポリシーの判断を生成します(手順4)。PDP の判断に基づき、マイクロサービスは認可を適用します(手順5)。
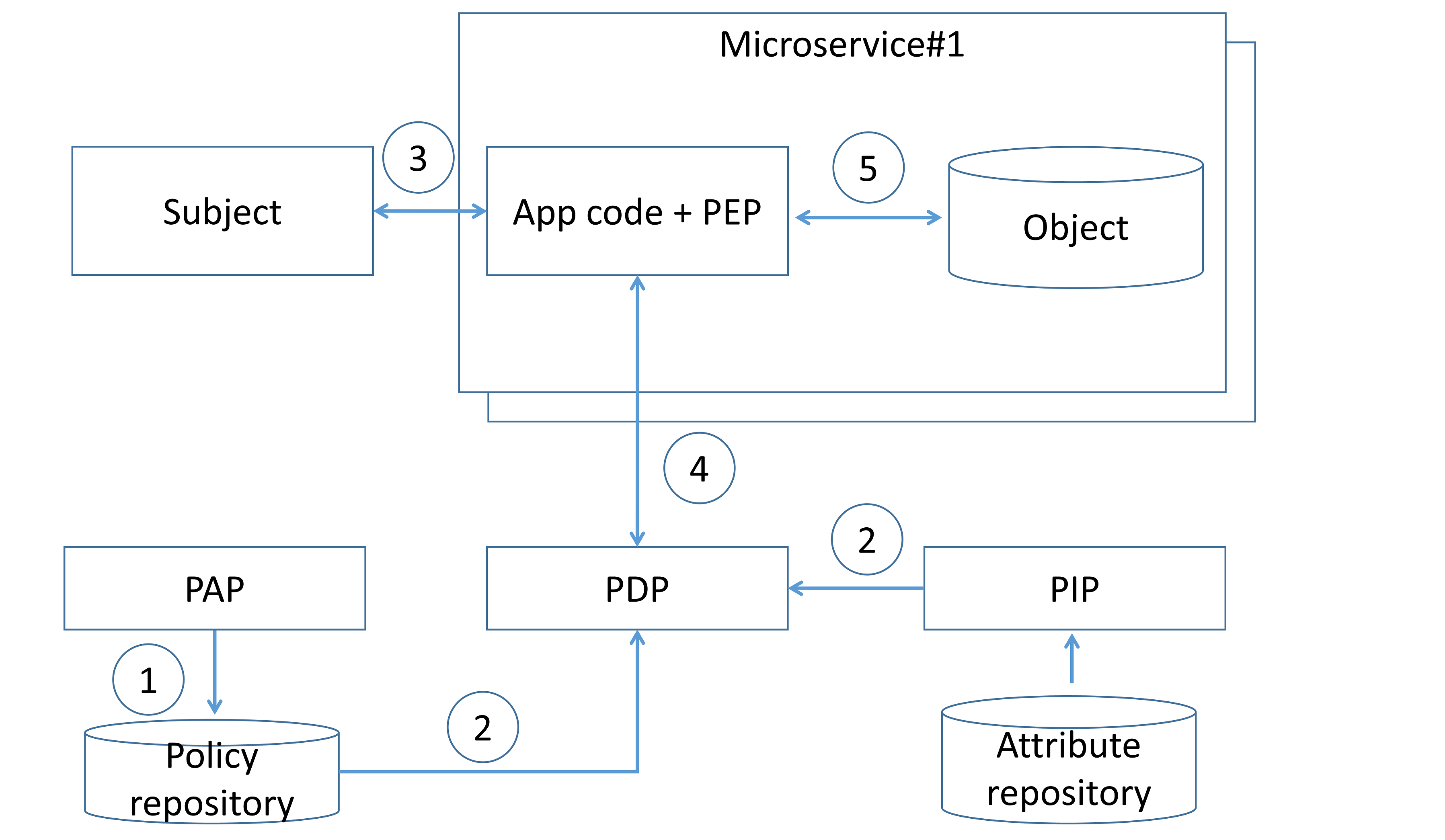
アクセス制御ルールを定義するために、開発/運用チームは何らかの言語または記法を使用する必要があります。例としては、ポリシールールを記述する標準である XACML(Extensible Access Control Markup Language)や NGAC(Next Generation Access Control)があります。
このパターンは、PDP の遠隔エンドポイントへの追加のネットワーク呼び出しによりレイテンシの問題を引き起こす可能性がありますが、マイクロサービス側で認可ポリシーの判断をキャッシュすることで軽減できます。なお、復元力と可用性の問題を防ぐため、PDP は高可用性モードで運用される必要があります。アプリケーション・セキュリティ・アーキテクトは、「多層防御」の原則を実現するために、これを他のパターン(例:API ゲートウェイ層での認可)と組み合わせるべきです。
埋め込みポリシー決定ポイントを用いた集中型パターン
このパターンでは、アクセス制御ルールは集中管理して定義されますが、保存と評価はマイクロサービスのレベルで行われます。アクセス制御ルールは PAP を用いて定義され(手順1)、それらのルールの評価に必要な属性とともに埋め込みの PDP に届けられます(手順2)。主体がマイクロサービスのエンドポイントを呼び出すと(手順3)、マイクロサービスのコードは PDP を呼び出し、PDP はクエリ入力をアクセス制御ルールと属性に対して評価することでアクセス制御ポリシーの判断を生成します(手順4)。PDP の判断に基づき、マイクロサービスは認可を適用します(手順5)。
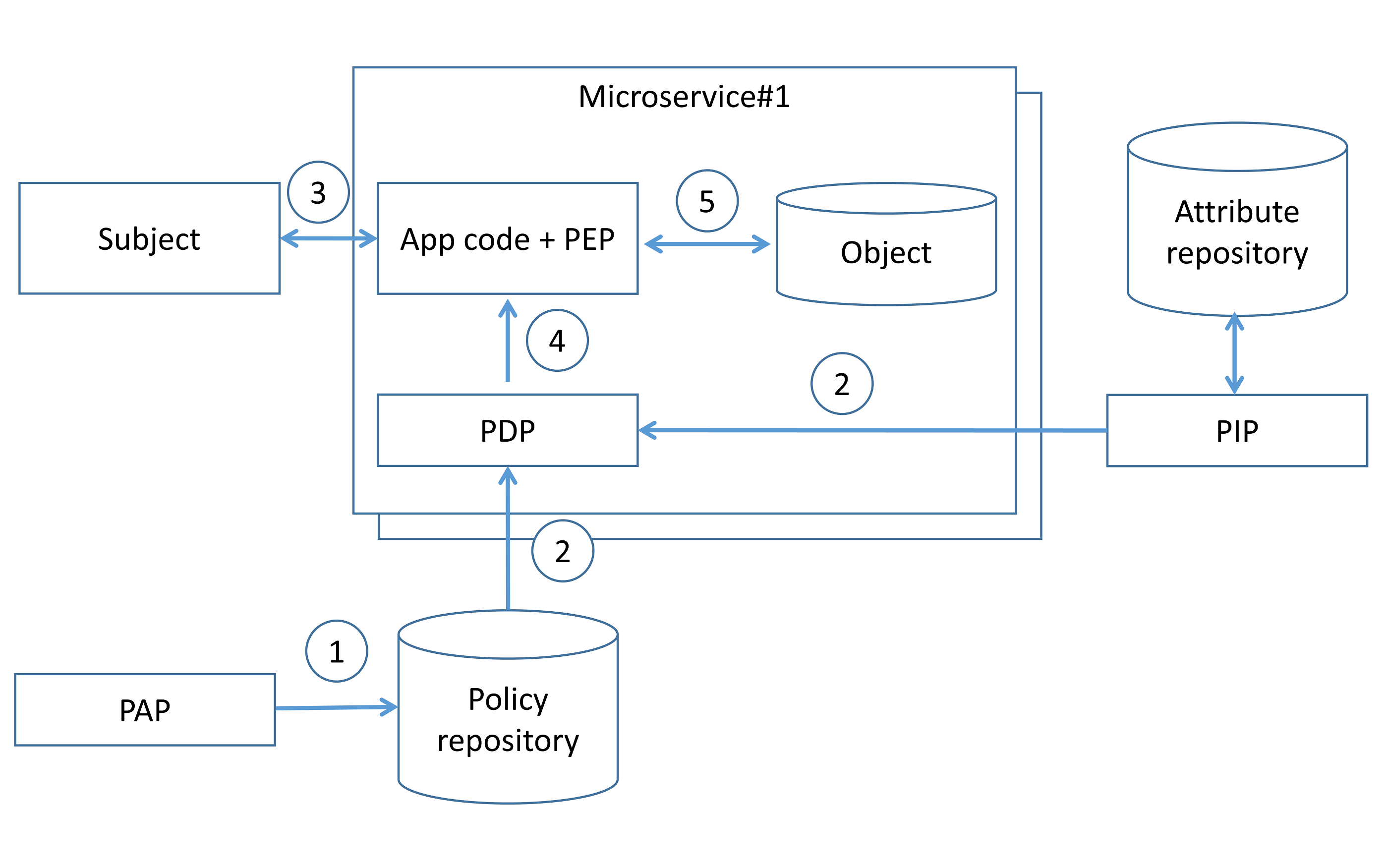
この場合の PDP コードは、マイクロサービスの組み込みライブラリ、またはサービスメッシュ・アーキテクチャにおけるサイドカーとして実装できます。ネットワーク/ホスト障害やネットワーク遅延の可能性を考慮し、埋め込み PDP は同一ホスト上(マイクロサービスと同じホスト)で動作するマイクロサービス・ライブラリまたはサイドカーとして実装することが望ましいです。埋め込み PDP は通常、認可の適用中に外部依存を最小化し低遅延を得るため、認可ポリシーおよびポリシー関連データをインメモリで保存します。「単一のポリシー決定ポイントを用いた集中型パターン」との主な違いは、認可の_判断_をマイクロサービス側に保存しない点にあり、最新の認可_ポリシー_をマイクロサービス側に保存することです。認可判断のキャッシュは、古い認可ルールの適用やアクセス制御違反につながる可能性がある点に注意が必要です。
Netflix は、マイクロサービスレベルでの認可実装にこの「埋め込み PDP を用いた集中型パターン」を用いた実例を提示しています(link、link)。
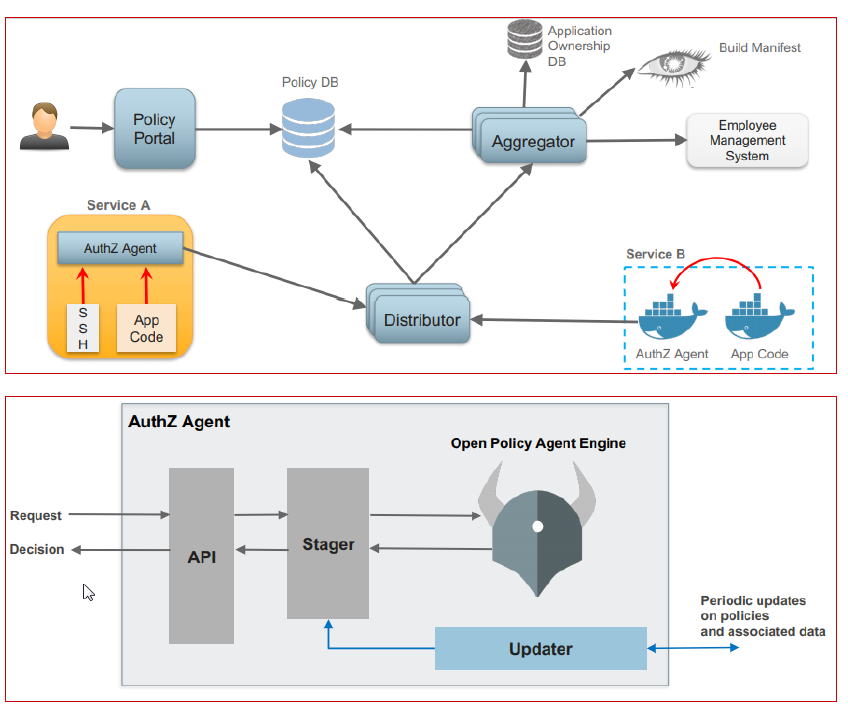
- Policy portal と Policy repository は、アクセス制御ルールの作成、管理、バージョニングを行う UI ベースのシステムです。
- Aggregator は、アクセス制御ルールで使用されるデータをすべての外部ソースから取得し、最新の状態に保ちます。
- Distributor は、アクセス制御ルール(Policy repository から)およびアクセス制御ルールで使用されるデータ(Aggregators から)を取得し、PDP 群に配布します。
- PDP(ライブラリ)は、アクセス制御ルールとデータを非同期に取得して最新に保ち、PEP コンポーネントによる認可適用を可能にします。
認可の実装に関する推奨事項
- スケーラビリティを達成するため、認可ポリシーをソースコードにハードコードする(分散型パターン)のではなく、ポリシー表現のための専用言語を使用することが望ましい。目標は、ゲートウェイ/プロキシを単なるチェックポイントとして置くことではなく、認可をコードから外部化/分離することである。サービス層の認可には、復元力と広い採用実績から「埋め込み PDP を用いた集中型パターン」を推奨する。
- 認可ソリューションはプラットフォームレベルのソリューションであるべきで、専任チーム(例:プラットフォーム・セキュリティ・チーム)が、認可ソリューションの開発と運用に責任を持つとともに、認可を実装したマイクロサービスのブループリント/ライブラリ/コンポーネントを開発チーム間で共有すべきである。
- 認可ソリューションは広く使われている解決策に基づくべきであり、カスタムソリューションの実装には以下の欠点がある:
- セキュリティ/エンジニアリングチームがカスタムソリューションを構築・保守しなければならない。
- システムアーキテクチャで使用されるあらゆる言語向けにクライアントライブラリ SDK を構築・保守する必要がある。
- すべての開発者に対してカスタム認可サービスの API と統合方法のトレーニングが必要であり、情報源となる OSS コミュニティが存在しない。
- すべてのアクセス制御ポリシーがゲートウェイ/プロキシや共有の認可ライブラリ/コンポーネントで強制できるとは限らないため、一部の特定のアクセス制御ルールは、マイクロサービスのビジネスコードレベルで実装する必要がある可能性がある。これに対処するため、マイクロサービス開発チームが、そうしたセキュリティ要件を洗い出し、マイクロサービス開発の過程で適切に扱えるよう、簡易な質問票/チェックリストを用いることが望ましい。
- 「多層防御」の原則を実装し、以下のレイヤで認可を適用することが望ましい:
- ゲートウェイおよびプロキシ層:粗い粒度での適用。
- マイクロサービス層:共有の認可ライブラリ/コンポーネントを用いて細粒度な判断を適用。
- マイクロサービスのビジネスコード層:ビジネス特有のアクセス制御ルールを実装。
- アクセス制御ポリシーについて、開発・承認・ロールアウトに関する正式な手続きを実装すること。
外部エンティティのアイデンティティ伝播
マイクロサービスレベルで細粒度な認可判断を行うには、マイクロサービスが呼び出し元のコンテキスト(例:ユーザー ID、ユーザーのロール/グループ)を理解する必要があります。内部サービス層で認可を適用できるよう、エッジ層は、認証済みの外部エンティティのアイデンティティ(例:エンドユーザーのコンテキスト)を、下流のマイクロサービスへのリクエストとともに伝播させる必要があります。外部エンティティのアイデンティティを伝播する最も単純な方法の一つは、エッジが受け取ったアクセストークンを再利用し、それを内部マイクロサービスに渡すことです。しかし、このアプローチは外部アクセストークンの漏えいの可能性により非常に危険であり、また、通信が独自のトークンベースのシステム実装に依存するため攻撃面が広がる可能性があります。もし内部サービスが意図せず外部ネットワークへ露出した場合、漏えいしたアクセストークンを用いて直接アクセスされ得ます。内部サービスが内部サービスのみに知られたトークン形式のみを受け入れる場合、この攻撃は成立しません。このパターンは、外部アクセストークンに依存しないわけではありません。すなわち、内部サービスは外部アクセストークンを理解し、さまざまな種類の外部トークン(例:JWT、Cookie、OpenID Connect トークン)からアイデンティティを抽出するための幅広い認証手法をサポートする必要があります。
アイデンティティ伝播:既存のパターン
外部エンティティのアイデンティティを平文または自己署名データ構造として送る
このアプローチでは、マイクロサービスは受信リクエストから外部エンティティのアイデンティティを抽出(例:受信したアクセストークンをパース)し、そのコンテキストを含むデータ構造(例:JSON または自己署名 JWT)を作成し、内部マイクロサービスへ渡します。このシナリオでは、受信側のマイクロサービスは呼び出し元マイクロサービスを信頼する必要があります。もし呼び出し元マイクロサービスがアクセス制御ルールに違反しようとすれば、HTTP ヘッダー内のユーザー/クライアント ID やユーザーロールを任意に設定することで可能になってしまいます。このアプローチは、すべてのマイクロサービスが、セキュアなソフトウェア開発プラクティスを適用する信頼できる開発チームによって開発されている、高い信頼環境にのみ適しています。
信頼できる発行者が署名したデータ構造を使用する
このパターンでは、エッジ層の認証サービスにより外部リクエストが認証された後、外部エンティティのアイデンティティ(例:ユーザー
ID、ユーザーのロール/グループ、または権限)を表すデータ構造が生成され、信頼できる発行者によって署名または暗号化され、内部マイクロサービスへ伝播されます。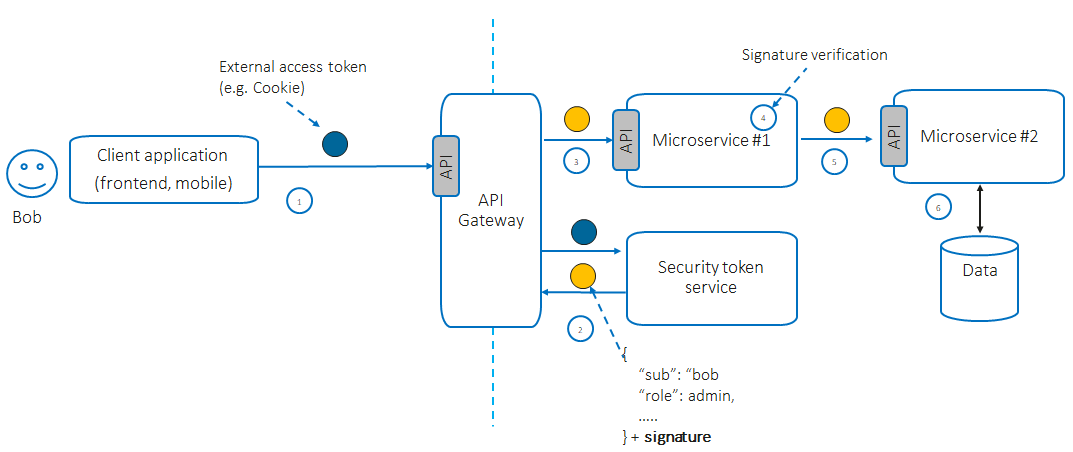
Netflix は、このパターンの実例として「Passport」と呼ばれる構造を提示しています。これはユーザー ID とその属性を含み、各受信リクエストについてエッジ層で HMAC によって保護されます。この構造は内部マイクロサービスに伝播され、外部に公開されることはありません。
- エッジ認証サービス(EAS)は、鍵管理システムから秘密鍵を取得します。
- EAS は、受信リクエストからアクセストークン(例:Cookie、JWT、OAuth2 トークン)を受け取ります。
- EAS はアクセストークンを復号し、外部エンティティのアイデンティティを解決し、署名済みの「Passport」構造で内部サービスに送信します。
- 内部サービスは、ラッパーを用いてユーザー・アイデンティティを抽出し(例:アイデンティティベースの認可を実装するために)利用できます。
- 必要に応じて、内部サービスは呼び出し連鎖の下流サービスに「Passport」構造を伝播させることができます。
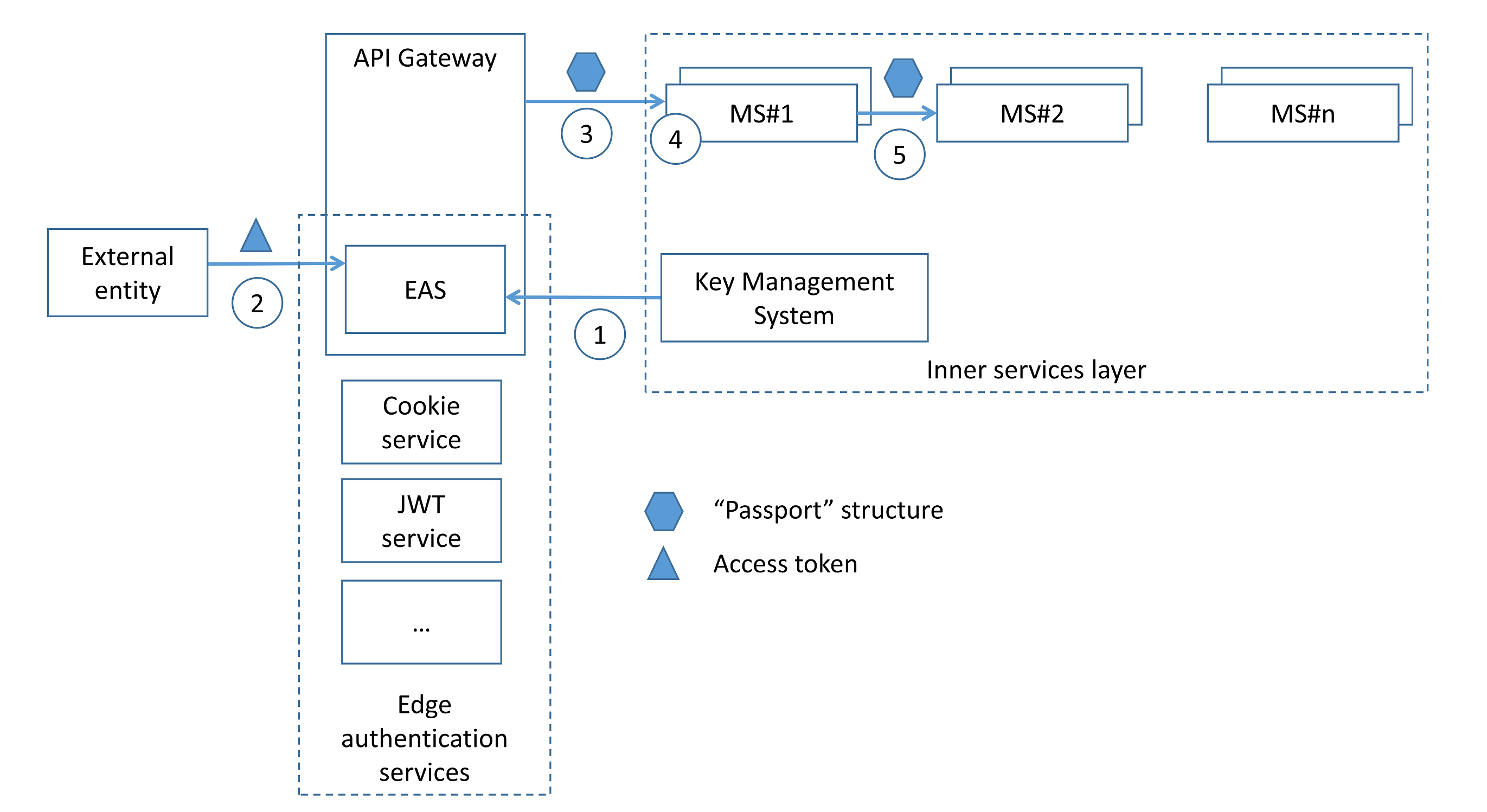 このパターンは外部アクセストークンに依存せず、外部エンティティとその内部表現の分離を可能にすることに留意すべきです。
このパターンは外部アクセストークンに依存せず、外部エンティティとその内部表現の分離を可能にすることに留意すべきです。
アイデンティティ伝播の実装に関する推奨事項
- 外部エンティティに発行されたアクセストークンと、その内部表現を切り離し、外部アクセストークンに依存せず拡張可能なシステムを実装すること。単一のデータ構造を用いて、マイクロサービス間で外部エンティティのアイデンティティを表現・伝播する。エッジ層のサービスは、受信した外部アクセストークンを検証し、内部エンティティ表現の構造を発行し、下流サービスへ伝播させる必要がある。
- 信頼できる発行者によって署名(対称または非対称暗号)された内部エンティティ表現構造を用いることは、コミュニティに採用されている推奨パターンである。
- 内部エンティティ表現構造は拡張可能であるべきで、より多くのクレームを追加できるようにし、低遅延につながる可能性を持たせる。
- 内部エンティティ表現構造は外部(例:ブラウザや外部デバイス)に公開してはならない。
サービス間認証
既存のパターン
相互トランスポート層セキュリティ(mTLS)
mTLS アプローチでは、各マイクロサービスは、機密性と完全性の達成に加え、自身が通信相手を正当に識別できます。デプロイ内の各マイクロサービスは公開鍵/秘密鍵ペアを保持し、その鍵ペアを用いて mTLS を介して受信側マイクロサービスに対して認証を行う必要があります。mTLS は通常、セルフホストの公開鍵基盤(PKI)によって実装されます。mTLS 使用時の主な課題は、鍵のプロビジョニングと信頼のブートストラップ、証明書失効、および鍵ローテーションです。
トークンベース
トークンベースのアプローチはアプリケーション層で動作します。トークンは、呼び出し元
ID(マイクロサービス
ID)およびその権限(スコープ)を含み得るコンテナです。呼び出し元マイクロサービスは、自身のサービス
ID
とパスワードを用いて特別なセキュリティ・トークン・サービスを呼び出し、署名済みのトークンを取得し、それをすべての送信リクエストに(例:HTTP
ヘッダーで)添付します。呼び出し先マイクロサービスはトークンを抽出し、オンラインまたはオフラインで検証できます。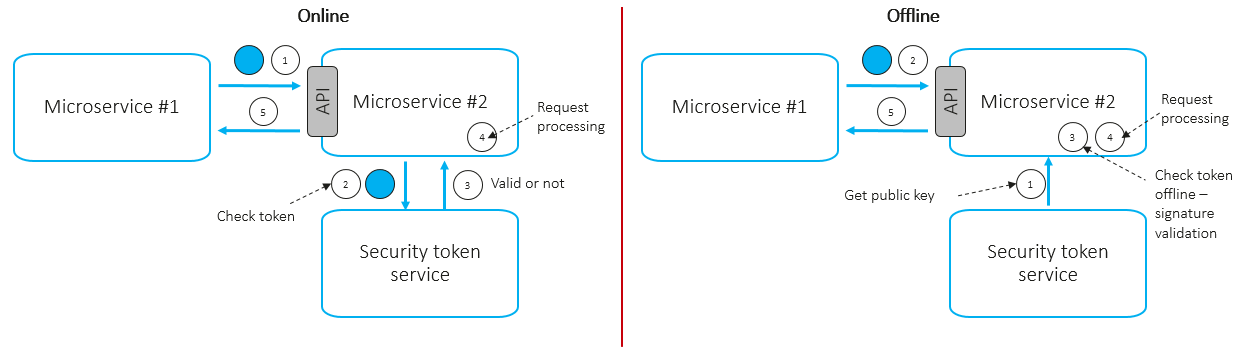
- オンライン・シナリオ:
- 受信トークンを検証するため、マイクロサービスはネットワーク呼び出しによって集中管理されたサービス・トークン・サービスを呼び出す。
- 失効(侵害)したトークンを検出できる。
- 高いレイテンシ。
- クリティカルなリクエストに適用すべき。
- オフライン・シナリオ:
- 受信トークンを検証するため、マイクロサービスはダウンロード済みのサービス・トークン・サービス公開鍵を使用する。
- 失効(侵害)したトークンを検出できない可能性がある。
- 低いレイテンシ。
- 非クリティカルなリクエストに適用すべき。多くの場合、トークンベース認証は TLS 上で動作し、転送中データの機密性と完全性を提供する。
ロギング
マイクロサービスベースのシステムにおけるロギングサービスは、説明責任(accountability)と追跡可能性(traceability)の原則を満たし、ログ分析を通じて運用におけるセキュリティ異常の検出を支援することを目的としています。したがって、アプリケーション・セキュリティ・アーキテクトが、マイクロサービスベースのシステムにおいて監査ロギングを実装するために、既存のアーキテクチャ・パターンを理解し適切に活用することが重要です。以下の図に高レベルのアーキテクチャ設計を示しますが、これは次の原則に基づきます。
- 各マイクロサービスは、標準出力(stdout、stderr)を用いてローカルファイルにログメッセージを書き込みます。
- ログ収集エージェントは定期的にログメッセージを取得し、それらをメッセージブローカー(例:NATS、Apache Kafka)に送信(発行)します。
- 中央ロギングサービスはメッセージブローカーのメッセージを購読し、それらを受信・処理します。
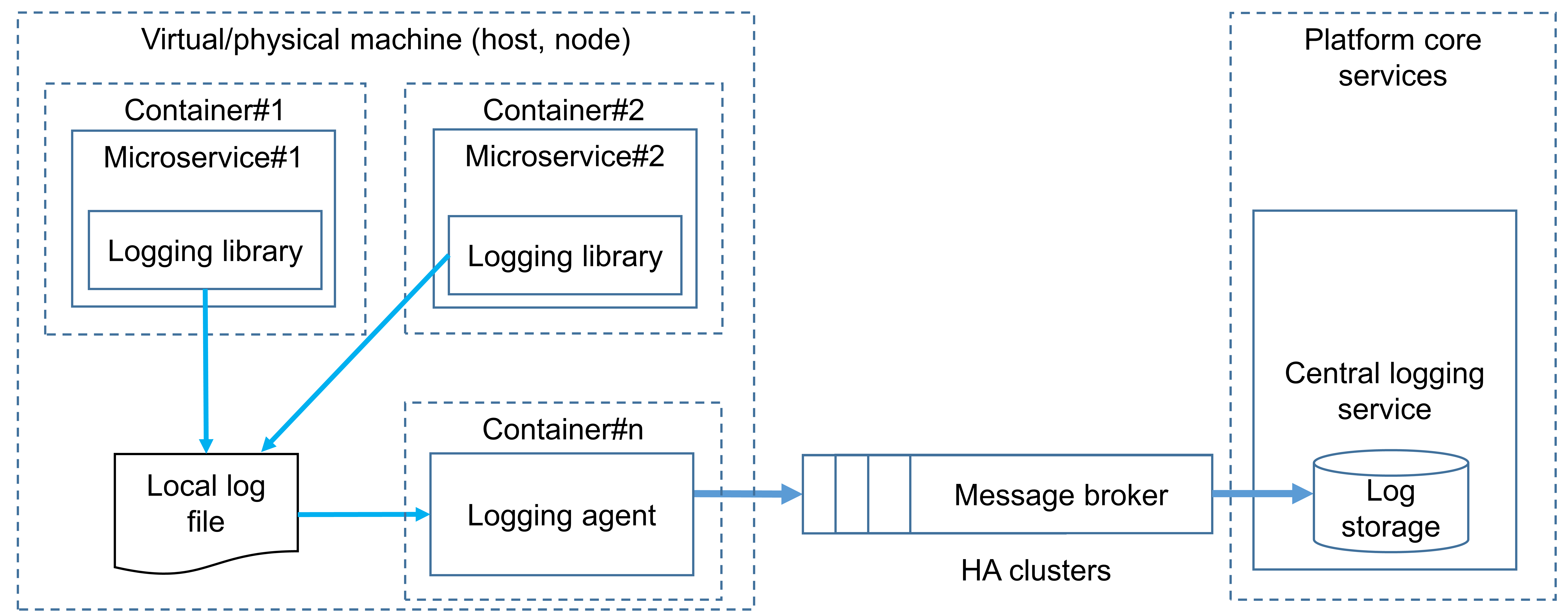
ロギング・サブシステムのアーキテクチャに関する高レベルの推奨とその根拠は以下の通りです。
- マイクロサービスはネットワーク通信を用いて中央ロギング・サブシステムに直接ログメッセージを送信してはならない。マイクロサービスはローカルのログファイルにログメッセージを書き込むべきである:
- これは、正当なマイクロサービスによるフラッディングや攻撃によるロギングサービス障害に起因するデータ損失の脅威を軽減する。
- ロギングサービスが停止した場合でも、マイクロサービスはローカルファイルにログを書き込み続ける(データ損失なし)。ロギングサービスが復旧後、ログは出荷(shipping)可能な状態で利用できる。
- マイクロサービスから切り離された専用コンポーネント(ログ収集エージェント)が存在するべきである。ログ収集エージェントは、マイクロサービス上でログデータを収集(ローカルログファイルを読み取り)し、中央ロギング・サブシステムへ送信するべきである。ネットワーク遅延の問題の可能性を考慮し、ログ収集エージェントはマイクロサービスと同一ホスト(仮想/物理マシン)にデプロイされるべきである:
- これは、正当なマイクロサービスによるフラッディングや攻撃によるロギングサービス障害に起因するデータ損失の脅威を軽減する。
- ログ収集エージェントが障害を起こしても、マイクロサービスはログファイルへ書き込み続ける。エージェント復旧後、ファイルを読み取り、メッセージブローカーへ情報を送る。
- 中央ロギング・サブシステムへの DoS 攻撃の可能性に鑑み、ログ収集エージェントは、ログメッセージ送信に非同期のリクエスト/レスポンス・パターンを用いてはならない。ログ収集エージェントと中央ロギングサービス間の非同期接続を実装するため、メッセージブローカーを設けるべきである:
- これは、正当なマイクロサービスによるフラッディング時におけるロギングサービス障害に起因するデータ損失の脅威を軽減する。
- ロギングサービスが停止した場合でも、マイクロサービスはローカルファイルにログを書き込み続ける(データ損失なし)。ロギングサービスが復旧後、ログは出荷可能な状態で利用できる。
- ログ収集エージェントとメッセージブローカーは、相互認証(例:TLS ベース)を用いて、送信されるすべてのデータ(ログメッセージ)を暗号化し、互いに認証するべきである:
- これは、マイクロサービスなりすまし、ロギング/転送システムなりすまし、ネットワークトラフィックの注入、ネットワークトラフィックの盗聴といった脅威を軽減する。
- メッセージブローカーは、無許可アクセスを軽減し最小権限の原則を実装するため、アクセス制御ポリシーを強制するべきである:
- これは、マイクロサービスの権限昇格の脅威を軽減する。
- ログ収集エージェントは、出力ログメッセージをフィルタ/サニタイズし、機微データ(例:個人情報、パスワード、API キー)が中央ロギング・サブシステムへ送信されないようにするべきである(データ最小化の原則)。ログから除外すべき項目の包括的な一覧については、OWASP Logging Cheat Sheetを参照のこと。
- マイクロサービスは、各呼び出し連鎖を一意に識別し、調査のためにログメッセージをグループ化するのに役立つ相関 ID(correlation ID)を生成すべきである。ログ収集エージェントは、すべてのログメッセージに相関 ID を含めるべきである。
- ログ収集エージェントは、その可用性/非可用性を示すヘルスとステータスデータを定期的に提供すべきである。
- ログ収集エージェントは、構造化ログ形式(例:JSON、CSV)でログメッセージを発行すべきである。
- ログ収集エージェントは、プラットフォーム・コンテキスト(ホスト名、コンテナ名)、ランタイム・コンテキスト(クラス名、ファイル名)などのコンテキストデータをログメッセージに付与すべきである。
どのイベントをログに記録すべきか、また可能なデータ形式の包括的な概要については、OWASP Logging Cheat SheetおよびApplication Logging Vocabulary Cheat Sheetを参照してください。
参考文献
- NIST Special Publication 800-204 “Security Strategies for Microservices-based Application Systems”
- NIST Special Publication 800-204A “Building Secure Microservices-based Applications Using Service-Mesh Architecture”
- Microservices Security in Action, Prabath Siriwardena and Nuwan Dias, 2020, Manning