Zanzibar: Google's Consistent, Global Authorization System
Ruoming Pang, 1 Ram´ on C´ aceres, 1 Mike Burrows, 1 Zhifeng Chen, 1 Pratik Dave, 1 Nathan Germer, 1 Alexander Golynski, 1 Kevin Graney, 1 Nina Kang, 1 Lea Kissner, 2 ∗ Jeffrey L. Korn, 1 Abhishek Parmar, 3 ∗ Christina D. Richards, 1 Mengzhi Wang 1 Google, LLC; 1 Humu, Inc.; 2 Carbon, Inc. 3
{rpang,caceres}@google.com
要約(Abstract)
オンラインの利用者がデジタルオブジェクトへのアクセスを許可されているかどうかを判定することは、プライバシー保護の中核となる。本論文では、アクセス制御リストを保存および評価するためのグローバルなシステムである Zanzibar の設計・実装・運用について述べる。Zanzibar は、Calendar、Cloud、Drive、Maps、Photos、YouTube を含む Google の数百に及ぶクライアントサービスからの幅広いアクセス制御ポリシーを表現するために、統一されたデータモデルと構成言語を提供する。その認可(authorization)の決定は、ユーザ操作の因果順序を尊重し、アクセス制御リストやオブジェクト内容の変更が行われる中でも外部一貫性(external consistency)を提供する。Zanzibar は、数兆件のアクセス制御リストと、1 秒あたり数百万件の認可リクエストにスケールし、数十億人が利用するサービスを支えている。本番運用 3 年間にわたり、95 パーセンタイル遅延を 10 ミリ秒未満、可用性を 99.999% 超で維持している。
1 序論(Introduction)
多くのオンラインでのやり取りでは、ユーザがデジタルオブジェクトに対してある操作を行う権限を持っていることを確認するための認可チェックが必要とされる。たとえば、ウェブベースの写真ストレージサービスは通常、写真の所有者が一部の写真を友人と共有する一方で、他の写真は非公開にしておくことを可能にする。そのようなサービスは、ユーザに写真を表示する前に、その写真が当該ユーザと共有されているかどうかを確認しなければならない。堅牢な認可チェックは、オンラインプライバシーを保護するうえで中心的な役割を果たす。
本論文では、権限情報(permissions)を保存し、その保存された権限情報に基づいて認可チェックを実行するためのシステムである Zanzibar を紹介する。これは、Calendar、Cloud、Drive、Maps、Photos、YouTube など、Google が提供する幅広いサービスで利用されている。これらのサービスのいくつかは、10 億人を超えるユーザを代表して数十億のオブジェクトを管理している。
個々のアプリケーションごとに独立したアクセス制御メカニズムを維持するのに比べて、統一された認可システムには重要な利点がある。第一に、それはアプリケーション間の一貫したセマンティクスとユーザー体験を確立するのに役立つ。
∗ Google 在籍時の業績。
第二に、アプリケーション同士の相互運用性を高める。たとえば、あるアプリケーションのオブジェクトの中に別のアプリケーションのオブジェクトが埋め込まれている場合に、アクセス制御を連携させることが容易になる。第三に、統一されたアクセス制御システムの上には有用な共通インフラストラクチャを構築できる。特に、アクセス制御を尊重し、かつアプリケーションをまたいで動作する検索インデックスなどが挙げられる。最後に、後述するように、認可にはデータ一貫性とスケーラビリティに関する特有の課題が存在する。これらの課題に対処するのをアプリケーションごとではなく一度で済ませることで、エンジニアリングリソースを節約できる。
Zanzibar システムに対して、我々は次のような目標を掲げる。
- Correctness(正しさ): アクセス制御の決定がユーザの意図を尊重する形で一貫性を確保しなければならない。
- Flexibility(柔軟性): コンシューマ向けおよびエンタープライズ向けアプリケーションの双方から要求される、豊富なアクセス制御ポリシーをサポートしなければならない。
- Low latency(低遅延): 認可チェックはしばしばユーザとの対話のクリティカルパス上にあるため、迅速に応答しなければならない。特に、検索結果の提供時には、しばしば数十から数百のチェックが必要になるため、テイルレイテンシ(遅延の裾)の低さが重要となる。
- High availability(高可用性): 明示的な認可が存在しない場合、クライアントサービスはユーザへのアクセスを拒否せざるを得なくなるため、要求に対して信頼性高く応答しなければならない。
- Large scale(大規模性): 数十億のユーザによって共有される数十億のオブジェクトを保護する必要がある。また、クライアントおよびそのエンドユーザの近くに配置されるよう、世界中にデプロイされなければならない。
Zanzibar は、これらの目標を、いくつかの注目すべき特徴の組み合わせによって達成している。柔軟性を提供するために、Zanzibar はシンプルなデータモデルと強力な構成言語を組み合わせている。この言語を用いることで、クライアントは owner(所有者)、editor(編集者)、commenter(コメント投稿者)、viewer(閲覧者)といった、ユーザとオブジェクトの任意の関係を定義できる。また、これらのユーザ–オブジェクト関係に基づいて、潜在的に複雑なアクセス制御ポリシーを指定するための、積集合や和集合といった集合演算的な(set-algebraic)演算子も含まれている。たとえば、あるアプリケーションは、「ドキュメントに編集権限を付与されたユーザにはコメント投稿も許可するが、すべてのコメント投稿者に編集権限を与えるわけではない」といったポリシーを指定できる。
実行時には、Zanzibar はクライアントに対してリモートプロシージャコール(RPC)インターフェースを通じてアクセス制御リスト(ACL)の作成・変更・評価を可能にする。単純な ACL は「ユーザ U がオブジェクト O に対して関係 R を持つ」という形式をとる。より複雑な ACL は「ユーザ集合 S がオブジェクト O に対して関係 R を持つ」という形式をとり、ここで S 自体が別のオブジェクト–関係の組によって指定される。したがって ACL は他の ACL を参照することができる。たとえば、「ある動画にコメントできるユーザの集合は、その特定の動画に対する閲覧権限を付与されたユーザと、その動画チャンネルに対する閲覧権限を持つユーザから構成される」といった指定が可能である。
グループメンバーシップは、ACL の重要なクラスであり、ここではオブジェクトがグループであり、その関係は意味的には member(メンバー)と同等である。グループは他のグループを含むことができ、これは Zanzibar が直面する課題の 1 つを示している。すなわち、あるユーザがグループに属しているかどうかを評価するには、長くネストしたグループメンバーシップの連鎖をたどる必要が生じうるということだ。
認可チェックは、「ユーザ U がオブジェクト O に対して関係 R を持っているか?」という形式をとり、分散サーバの集合によって評価される。チェックリクエストが Zanzibar に到着すると、そのチェックを評価するための処理は複数のサーバへ扇状に広がる可能性がある。たとえば、あるグループが個々のメンバーと他のグループの両方を含んでいる場合などである。これらのサーバのそれぞれが、たとえばグループメンバーシップの階層を再帰的にたどるために、別のサーバに連絡することもある。
Zanzibar は複数の次元にわたってグローバルスケールで動作している。2 兆を超える ACL を保存し、1 秒あたり数百万件の認可チェックを実行している。任意のオブジェクトに対する認可チェックが世界のどこからでも行われうるため、ACL データは地理的なパーティショニングに適さない。このため、Zanzibar はすべての ACL データを、地理的に分散した数十のデータセンタに複製し、世界中にある数千台のサーバに負荷を分散している。
Zanzibar は、相互に関連した 2 つの特徴を通じて、アクセス制御決定のグローバルな一貫性をサポートする。1 つ目は、基盤となるデータストアに ACL の変更がコミットされる順序を尊重することである。2 つ目は、認可チェックが、クライアントが指定したある変更以降の ACL データに基づくことを保証できることである。したがって、たとえばクライアントは、あるユーザをグループから削除した後、その削除を反映したメンバーシップチェックの結果が得られることを保証される。Zanzibar は、外部一貫性保証を備えたグローバル分散データベースシステムに ACL を保存することで、これらの順序に関する性質を提供する [15, 18]。
Zanzibar は、このグローバルに分散した環境で低遅延かつ高可用性を達成するために、さまざまな手法を用いている。その一貫性プロトコルにより、ほとんどのリクエストはリージョン間の往復通信を必要とせず、ローカルに複製されたデータのみで処理できる。Zanzibar は一貫性のためにデータを正規化された形式で保存する。正規化されたデータ上でホットスポットが発生する場合には、最終的な結果および中間結果をキャッシュし、同時発生するリクエストを重複除去することで対処する。また、ヘッジリクエスト(hedging requests)のような手法や、限定的な非正規化(denormalization)を伴う深くネストした集合に対する計算の最適化なども適用している。Zanzibar は、認可チェックの 95% 超に対して 10 ミリ秒以内に応答し、過去 3 年間にわたり 99.999% 超の可用性を維持してきた。
本論文の主な貢献は、一貫した、世界規模の認可システムを構築しデプロイするうえでのエンジニアリング上の課題を伝えることにある。Zanzibar の設計要素の多くは既存研究に根ざしているものの、本論文は、正しさ、柔軟性、レイテンシ、可用性、およびスケーラビリティに関する厳しい要件を満たすために Zanzibar が組み合わせている機能や手法の記録を提供する。また、多様で要求の厳しいクライアント群に対して Zanzibar を運用してきた経験から得られた教訓についても強調する。
2 Model, Language, and API
この章では、Zanzibar のデータモデル、構成言語、およびアプリケーション・プログラミング・インタフェース (API) について説明する。
2.1 Relation Tuples
Zanzibar において、ACL はリレーションタプル (relation tuples) として表現されるオブジェクト–ユーザ、またはオブジェクト–オブジェクトの関係の集合である。グループは、単にメンバーシップのセマンティクスを持つ ACL である。リレーションタプルは効率的なバイナリエンコーディングを持つが、本論文では分かりやすいテキスト表記を用いて表す:
ここで、⟨namespace⟩ と ⟨relation⟩ はクライアントの構成 (§2.3) で事前定義されており、⟨object id⟩ は文字列、⟨user id⟩ は整数である。リレーションタプルを識別するために必要な主キーは、⟨namespace⟩、⟨object id⟩、⟨relation⟩、および ⟨user⟩ である。注目すべき特徴の 1 つは、⟨userset⟩ によって ACL がグループを参照できることであり、これによりネストしたグループメンバーシップの表現をサポートしている。
表 1 に、いくつかの例となるタプルとそれに対応するセマンティクスを示す。一部のリレーション (例: viewer) はアクセス制御を直接定義する一方で、他のリレーション (例: parent、フォルダを指す) はオブジェクト間の抽象的な関係のみを定義する。これらの抽象的な関係は、名前空間構成内で指定される userset リライトルール (§2.3.1) によって、間接的にアクセス制御に影響を与える場合がある。
我々のデータモデルを、オブジェクトごとの ACL ではなくタプルを中心に定義することで、ACL とグループの概念を統一し、後述する §2.4 の通り効率的な読み取りとインクリメンタルな更新をサポートできる。
2.2 Consistency Model
ACL チェックは、予期しない共有動作を避けるために、ユーザが ACL やオブジェクト内容を変更する順序を尊重しなければならない。具体的には、我々のクライアントは、ACL 更新の順序を尊重しなかったり、古い ACL を新しいコンテンツに適用したりすることで生じる「new enemy(新たな敵)」問題の防止を重視している。次の 2 つの例を考える:
表 1: リレーションタプルの例。#...
はタプルのセマンティクスに影響しないリレーションを表す。
| Example Tuple in Text Notation | Semantics |
|---|---|
| doc:readme#owner@10 | User 10 is an owner of doc:readme |
| group:eng#member@11 | User 11 is a member of group:eng |
| doc:readme#viewer@group:eng#member | Members of group:eng are viewers of doc:readme |
| doc:readme#parent@folder:A#... | doc:readme is in folder:A |
(テキスト表記でのタプル例) | (意味)
Example A: Neglecting ACL update order
- Alice がフォルダの ACL から Bob を削除する。
- その後 Alice が Charlie に、新しいドキュメントをそのフォルダに移動するよう依頼する。このときドキュメントの ACL はフォルダの ACL を継承する。
- Bob は新しいドキュメントを見られてはならないが、ACL チェックが 2 つの ACL 変更の順序を無視した場合、見えてしまう可能性がある。
Example B: Misapplying old ACL to new content
- Alice がドキュメントの ACL から Bob を削除する。
- その後 Alice が Charlie に、そのドキュメントに新しいコンテンツを追加するよう依頼する。
- Bob は新しいコンテンツを見られてはならないが、ACL チェックが Bob の削除前の古い ACL で評価された場合、新しいコンテンツが見えてしまう可能性がある。
「new enemy」問題を防ぐには、Zanzibar が ACL やコンテンツの更新の因果順序を理解し、尊重する必要がある。これには、異なる ACL やオブジェクトに対する更新、さらには Zanzibar からは見えないチャネルを介して調整される更新も含まれる。したがって、Zanzibar は 2 つの主要な一貫性特性を提供しなければならない: external consistency [18] と、bounded staleness を持つスナップショット読み取り (snapshot reads with bounded staleness) である。
External consistency により、Zanzibar は各 ACL またはコンテンツ更新にタイムスタンプを割り当てることができる。2 つの因果的に関連する更新 x ≺ y に対しては、その因果順序を反映するタイムスタンプ、すなわち Tx < Ty が割り当てられる。因果関係を反映したタイムスタンプがあれば、タイムスタンプ T における ACL データベースのスナップショット読み取り (T 以下のタイムスタンプを持つすべての更新を観測する) は、ACL 更新間の順序を尊重する。つまり、その読み取りが更新 x を観測するならば、x より因果的に前に起こったすべての更新を観測することになる。
さらに、古い ACL を新しいコンテンツに適用することを避けるため、ACL チェックを評価する際のスナップショットは、コンテンツ更新に割り当てられた因果タイムスタンプより古くあってはならない。タイムスタンプ Tc のコンテンツ更新があった場合、タイムスタンプ ≥ Tc のスナップショットで読み取ることで、そのコンテンツ更新より因果的に前に起こったすべての ACL 更新が ACL チェックによって観測されることが保証される。
External consistency と bounded staleness を持つスナップショット読み取りを実現するために、我々は ACL をグローバルデータベースシステム Spanner [15] に保存している。Spanner の TrueTime 機構は、各 ACL 書き込みにマイクロ秒精度のタイムスタンプを割り当てる。このタイムスタンプは書き込み間の因果順序を反映し、external consistency を提供する。我々は、複数のデータベース読み取りにわたって、各 ACL チェックを単一のスナップショットタイムスタンプで評価する。これにより、そのチェックのスナップショットタイムスタンプ以下のタイムスタンプを持つすべての書き込みのみが ACL チェックから見えることになる。
新しいコンテンツに対して古い ACL を用いたチェックを避けるために、常に最新のスナップショットでチェックを評価し、その結果がチェックコール時点までのすべての ACL 書き込みを反映するようにする、という方法も考えられる。しかし、そのような評価にはグローバルなデータ同期が必要であり、高レイテンシな往復通信と制限された可用性を伴う。代わりに、我々は Zanzibar クライアントとの協調によって、ほとんどのチェックをすでに複製済みのデータ上で評価できるようにする以下のプロトコルを設計した:
- Zanzibar クライアントは、コンテンツ変更が保存されようとするタイミングで、content-change ACL チェック (§2.4.4) を通じて、それぞれのコンテンツバージョンに対して zookie と呼ばれる不透明な一貫性トークンを要求する。Zanzibar は zookie に現在のグローバルタイムスタンプをエンコードし、それ以前のすべての ACL 書き込みがより小さいタイムスタンプを持つことを保証する。クライアントは、この zookie をコンテンツ変更とともにクライアント側ストレージに対してアトミックな書き込みで保存する。なお、content-change チェックは、アプリケーションのコンテンツ変更と同じトランザクション内で評価される必要はなく、ユーザがコンテンツを変更したタイミングでトリガされさえすればよい。
- クライアントは、その後の ACL チェックリクエストにこの zookie を送信し、チェックのスナップショットが、少なくともそのコンテンツバージョンのタイムスタンプと同程度に新しいことを保証する。
External consistency と、zookie によって制約される staleness を持つスナップショット読み取りは、「new enemy」問題を防止する。Example A では、ACL 更新 A1 と A2 には、それぞれ TA1 < TA2 のタイムスタンプが割り当てられる。Bob は Charlie によって追加された新しいドキュメントを見られない。なぜなら、T < TA2 でチェックが評価される場合、ドキュメントの ACL にフォルダの ACL が含まれておらず、T ≥ TA2 > TA1 で評価される場合には、フォルダ ACL から Bob を削除した更新 A1 をチェックが観測するからである。Example B では、Bob はドキュメントに追加された新しいコンテンツを見ることができない。Bob が新しいコンテンツを見るためには、チェックがコンテンツ更新に割り当てられたタイムスタンプ TB2 以上の zookie で評価されなければならない。しかし TB2 > TB1 であるため、そのようなチェックは、ACL から Bob を削除した ACL 更新 B1 も同時に観測することになる。
zookie プロトコルは、Zanzibar の一貫性モデルにおける重要な特徴である。これは、ACL 更新とコンテンツ更新の因果順序を Zanzibar が尊重することを保証しつつ、それ以外については、レイテンシと可用性の目標を満たすために Zanzibar が評価タイムスタンプを自由に選択できるようにしている。この自由度は、プロトコルの「少なくともこれと同程度に新しい (at-least-as-fresh)」というセマンティクスから生じており、Zanzibar は zookie にエンコードされたタイムスタンプより新しければ任意のタイムスタンプを選択できる。この自由度により、Zanzibar はほとんどのチェックを、すでに複製されたデータに対して既定の staleness で処理できるようになり (§3.2.1)、またホットスポットを避けるために評価タイムスタンプを量子化 (quantize) することも可能になる (§3.2.5)。
2.3 Namespace Configuration
クライアントが Zanzibar にリレーションタプルを保存する前に、自身の名前空間 (namespace) を構成しなければならない。名前空間構成では、その名前空間内のリレーションとストレージパラメータが指定される。各リレーションには名前があり、viewer や editor といったクライアント定義の文字列と、リレーション構成 (relation config) が対応している。ストレージパラメータには、シャーディング設定や、オブジェクト ID 用のエンコーディングが含まれる。これにより Zanzibar は、整数や文字列など、さまざまな形式のオブジェクト ID の保存を最適化できる。
2.3.1 Relation Configs and Userset Rewrites
リレーションタプルはオブジェクトとユーザの関係を反映しているが、それだけでは実際の (effective) ACL を完全には定義しない。たとえば、一部のクライアントは「各オブジェクトに対して editor 権限を持つユーザには、同じオブジェクトに対して viewer 権限も与える」といったポリシーを指定している。このような「リレーション間の関係」は、オブジェクトごとにリレーションタプルを 1 つずつ追加することでも表現できるが、名前空間内のすべてのオブジェクトに対してタプルを保存するのは非効率であり、すべてのオブジェクトに対する一括変更を困難にする。そこで我々は、リレーション構成内の userset リライトルールを通じて、オブジェクトに依存しない関係をクライアントが定義できるようにしている。図 1 は、同心円状のリレーションを持つシンプルな名前空間構成の例を示しており、viewer が editor を包含し、editor が owner を包含している。
Userset リライトルールは、名前空間内の各リレーションごとに定義される。各ルールは、オブジェクト ID を入力として受け取り、userset 式 (expression) の木を出力する関数を指定する。この木の各葉ノードは、次のいずれかになりうる:
- this: ⟨object # relation⟩ ペアに対する保存済みリレーションタプルから、すべてのユーザを返す。ここには、タプル内の userset から参照される間接的な ACL も含まれる。リライトルールが指定されていない場合のデフォルト動作はこれである。
- computed userset: 入力オブジェクトについて新しい userset を計算する。たとえば、viewer リレーションの userset 式が、同じオブジェクト上の editor userset を参照できるようにすることで、リレーション間の ACL 継承機能を提供できる。
- tuple to userset: 入力オブジェクトから tupleset (§2.4.1) を計算し、その tupleset に一致するリレーションタプルを取得し、取得した各リレーションタプルから userset を計算する。この柔軟なプリミティブにより、「ドキュメントの親フォルダを調べ、そのフォルダの viewer を継承する」といった複雑なポリシーをクライアントが表現できる。
Userset 式は、複数のサブ式から構成することもでき、union、intersection、exclusion といった演算によってそれらを組み合わせる。
name: "doc"
relation { name: "owner" }
relation {
name: "editor"
userset_rewrite {
union {
child { _this {} }
child { computed_userset { relation: "owner" } }
} } }
relation {
name: "viewer"
userset_rewrite {
union {
child { _this {} }
child { computed_userset { relation: "editor" } }
child { tuple_to_userset {
tupleset { relation: "parent" }
computed_userset {
object: $TUPLE_USERSET_OBJECT # parent folder
relation: "viewer"
} } }
} } }
図 1: ドキュメントに対して同心円状のリレーションを持つシンプルな名前空間構成。すべての owners は editors であり、すべての editors は viewers である。さらに、親フォルダの viewers もドキュメントの viewers となる。
2.4 API
Zanzibar は ACL チェックをサポートするだけでなく、クライアントがリレーションタプルを読み書きし、タプル更新を監視し、有効な ACL を検査するための API も提供する。
これらの API メソッド全体で用いられる概念として、zookie がある。Zookie は、ACL の書き込み、クライアントのコンテンツバージョン、または読み取りスナップショットを反映する、グローバルに意味のあるタイムスタンプをエンコードした不透明なバイト列である。ACL の読み取りおよびチェックリクエストにおける zookie は、スナップショット読み取りに対する staleness の上限を指定し、これによって Zanzibar の主要な一貫性特性の 1 つを提供する。我々は、クライアントが任意のタイムスタンプを選択してしまうことを防ぎ、将来の拡張余地を残すために、実際のタイムスタンプではなく不透明なクッキーを採用している。
2.4.1 Read
クライアントは、ユーザに ACL やグループメンバーシップを表示したり、後続の書き込みの準備をしたりするために、リレーションタプルを読み取る。読み取りリクエストは、1 つ以上の tupleset と、オプションの zookie を指定する。
各 tupleset は、リレーションタプルの集合のキーを指定する。この集合には、1 つのタプルキーだけを含めることも、名前空間内の特定のオブジェクト ID または userset を持つすべてのタプル(必要に応じてリレーション名で制約)のいずれかを含めることもできる。Tupleset を用いることで、クライアントは特定のメンバーシップエントリを参照したり、ACL またはグループ内のすべてのエントリを読み取ったり、あるユーザが直接メンバーとなっているグループをすべて検索したりできる。読み取りリクエスト内のすべての tupleset は、同じスナップショットで処理される。
Zookie を指定することで、クライアントは、書き込み応答に含まれていた zookie を読み取りリクエストに渡して、以前の書き込みよりも古くない読み取りスナップショットを要求することも、あるいは以前の読み取り応答の zookie を後続のリクエストに渡し、前回の読み取りと同じスナップショットでの読み取りを要求することもできる。リクエストに zookie が含まれていない場合、Zanzibar は適度に最近のスナップショットを選択し、zookie が指定された場合よりも低レイテンシな応答を提供できる可能性がある。
読み取り結果はリレーションタプルの内容のみに依存し、userset リライトルールは反映しない。たとえば、viewer userset が常に owner userset を含むように構成されていたとしても、viewer リレーションでタプルを読み取っても、owner リレーションのタプルは返されない。有効な userset を理解する必要があるクライアントは、Expand API (§2.4.5) を利用できる。
2.4.2 Write
クライアントは、単一のリレーションタプルを変更して ACL を追加または削除することができる。また、楽観的同時実行制御 [21] を用いた read-modify-write プロセスを介して、オブジェクトに関連するすべてのタプルを変更することもできる。この場合、読み取り RPC に続いて書き込み RPC が行われる:
- オブジェクトに属するすべてのリレーションタプルを読み取る。ここには、オブジェクトごとの「ロック (lock)」タプルも含まれる。
- 書き込みまたは削除するタプルを生成する。ロックタプルが読み取り以降に変更されていない場合にのみ書き込みがコミットされる、という条件付きで、書き込みとロックタプルへの touch を Zanzibar に送信する。
- 書き込み条件が満たされない場合は、ステップ 1 に戻る。
ロックタプルは、クライアントが書き込み競合を検出するために利用する、通常のリレーションタプルに過ぎない。
2.4.3 Watch
一部のクライアントは、Zanzibar 内のリレーションタプルに対する二次インデックスを維持している。これを実現するために、Watch API を利用できる。Watch リクエストは、1 つ以上の名前空間と、監視を開始する時刻を表す zookie を指定する。Watch 応答には、リクエストされた開始タイムスタンプから、ウォッチ応答内に含まれるハートビート zookie にエンコードされたタイムスタンプまでの、すべてのタプル変更イベントがタイムスタンプ昇順で含まれる。クライアントは、このハートビート zookie を用いて、前回の Watch 応答が終了した地点から監視を再開できる。
2.4.4 Check
Check リクエストは、⟨object # relation⟩ で表される userset、しばしば認証トークンで表現される仮のユーザ (putative user)、および望ましいオブジェクトバージョンに対応する zookie を指定する。読み取りと同様、チェックは常に、指定された zookie 以降の時刻に対応する一貫したスナップショットで評価される。
アプリケーションのコンテンツ変更を認可するために、クライアントは content-change check と呼ばれる特別な種類の Check リクエストを送信する。Content-change check リクエストには zookie が含まれず、最新のスナップショットで評価される。コンテンツ変更が認可されると、Check 応答には zookie が含まれ、クライアントはこれをオブジェクトコンテンツとともに保存し、そのコンテンツバージョンに対する後続のチェックに利用する。この zookie は評価スナップショットをエンコードし、新しいコンテンツを保護する ACL 更新のタイムスタンプより大きくなるため、ACL 変更からコンテンツ変更へのあらゆる因果関係を捕捉する (§2.2)。
2.4.5 Expand
Expand API は、⟨object # relation⟩ ペアとオプションの zookie を受け取り、有効な userset を返す。Read API と異なり、Expand は userset リライトルールを通じて表現された間接参照をたどる。結果は userset 木として表現され、その葉ノードはユーザ ID または他の ⟨object # relation⟩ ペアを指す userset であり、中間ノードは union、intersection、exclusion 演算子を表す。Expand は、どのユーザやグループがオブジェクトにアクセスできるかという完全な集合についてクライアントが推論するうえで重要であり、アクセス制御されたコンテンツに対する効率的な検索インデックスを構築することを可能にする。
3 Architecture and Implementation
図 2 に Zanzibar システムのアーキテクチャを示す。aclservers は主要なサーバ種別であり、クラスターとして構成され、Check、Read、Expand、および Write リクエストに応答する。リクエストはクラスター内の任意のサーバに到達し、そのサーバは必要に応じて処理をクラスター内の他のサーバへ扇状に展開する。これらのサーバは、中間結果を計算するために、さらに他のサーバに連絡する場合がある。最初のサーバは最終結果を集約し、クライアントに返却する。
Zanzibar は、ACL とそのメタデータを Spanner データベースに保存する。各クライアント名前空間のリレーションタプルを保存するデータベースが 1 つ、すべての名前空間の構成を保持するデータベースが 1 つ、そしてすべての名前空間で共有される changelog データベースが 1 つ存在する。Aclservers は、クライアントリクエストに応答する過程で、これらのデータベースを読み書きする。
watchservers は、Watch リクエストに応答するための専用サーバ種別である。これらは changelog を末尾追跡 (tail) し、クライアントに対して名前空間の変更ストリームをほぼリアルタイムで提供する。
Zanzibar は、Spanner 内のすべての Zanzibar データに対して、さまざまなオフライン処理を行うためのデータ処理パイプラインを定期的に実行する。この処理の 1 つは、各名前空間のリレーションタプルについて、既知のスナップショットタイムスタンプでのダンプを生成することである。もう 1 つは、名前空間ごとに構成されたしきい値より古いタプルバージョンのガーベジコレクションである。
Leopard は、大きくて深くネストした集合上での操作を最適化するために用いられるインデクシングシステムである。これは ACL データの定期的なスナップショットを読み取り、スナップショット間の変更を監視する。さらにそのデータに対して、非正規化などの変換を行い、aclservers からのリクエストに応答する。
この章の残りでは、これらのアーキテクチャ要素の実装について、より詳細に述べる。
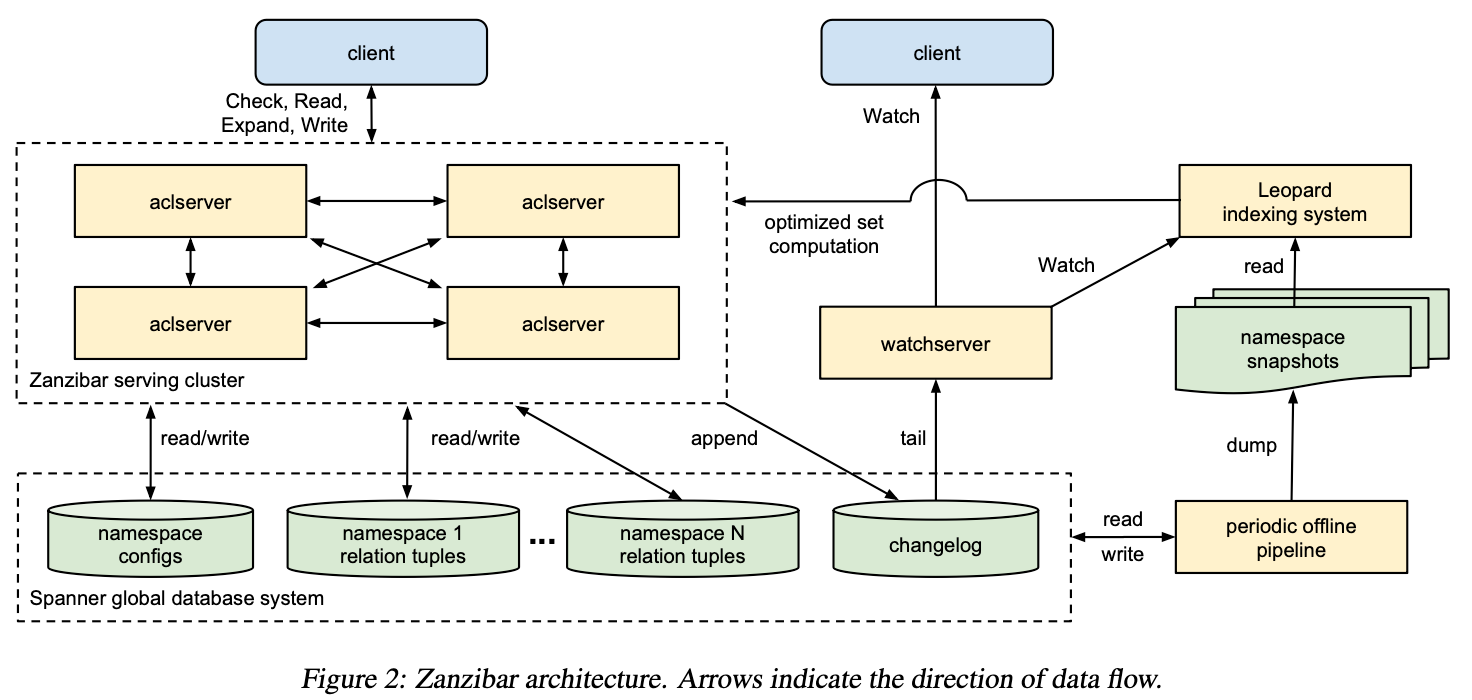
図 2: Zanzibar のアーキテクチャ。矢印はデータフローの方向を示す。
3 Architecture and Implementation
図 2 に Zanzibar システムのアーキテクチャを示す。aclserver は主要なサーバ種別であり、クラスターとして構成され、Check、Read、Expand、Write リクエストに応答する。リクエストはクラスター内の任意のサーバに到着し、そのサーバが必要に応じてクラスター内の他のサーバに処理をファンアウトする。これらのサーバは、中間結果を計算するために、さらに別のサーバに連絡する場合もある。最初にリクエストを受け取ったサーバが最終結果を集約し、クライアントに返す。
Zanzibar は、ACL とそのメタデータを Spanner データベースに保存する。各クライアント名前空間ごとにリレーションタプルを保存するデータベースが 1 つ、すべての名前空間構成を保持するデータベースが 1 つ、そしてすべての名前空間で共有される changelog データベースが 1 つ存在する。Aclserver は、クライアントリクエストに応答する過程で、これらのデータベースを読み書きする。
watchserver は Watch リクエストに応答するための専用サーバ種別である。これらは changelog を末尾追跡 (tail) し、名前空間の変更ストリームをほぼリアルタイムでクライアントに提供する。
Zanzibar は、Spanner 上のすべての Zanzibar データに対して様々なオフライン処理を実行するために、データ処理パイプラインを定期的に実行する。その 1 つの機能は、各名前空間のリレーションタプルについて、既知のスナップショットタイムスタンプにおけるダンプを生成することである。
Figure 2: Zanzibar architecture. Arrows indicate the direction of data flow.
もう 1 つの機能は、名前空間ごとに構成されたしきい値より古いタプルバージョンをガーベジコレクションすることである。
Leopard は、大きくて深くネストした集合上の操作を最適化するために用いられるインデクシングシステムである。これは ACL データの定期的なスナップショットを読み取り、スナップショット間の変更を監視する。その上で非正規化 (denormalization) などの変換を実行し、aclserver からのリクエストに応答する。
この節の残りでは、これらアーキテクチャ要素の実装について、より詳細に述べる。
3.1 Storage
3.1.1 Relation Tuple Storage
我々は、各名前空間のリレーションタプルを別々のデータベースに保存している。そこでは各行が、主キー (shard ID, object ID, relation, user, commit timestamp) によって識別される。複数のタプルバージョンは別々の行に保存されるため、ガーベジコレクションのウィンドウ内であれば任意のタイムスタンプでチェックや読み取りを評価できる。主キーの並び順により、特定の object ID または (object ID, relation) の組に対するすべてのリレーションタプルを検索できる。
クライアントは、自身のデータパターンに応じて名前空間のシャーディングを構成する。通常、shard ID は object ID のみに基づいて決定される。例えば、非常に多くのメンバーを持つグループを保存する名前空間など、場合によっては、shard ID が object ID と user の両方から計算されることもある。
3.1.2 Changelog
Zanzibar はまた、Watch API 用にタプル更新の履歴を保持する changelog データベースも管理している。主キーは (changelog shard ID, timestamp, unique update ID) であり、changelog shard は各書き込みごとにランダムに選択される。
Zanzibar のすべての書き込みは、単一トランザクション内で tuple storage と changelog shard の両方へコミットされる。我々は、保留中トランザクションが changelog 読み取りをブロックする時間を最小化するため、changelog shard をホストしている Spanner サーバをトランザクションコーディネータとして指定している。
3.1.3 Namespace Config Storage
名前空間構成 (namespace configs) は 2 つのテーブルを持つデータベースに保存される。1 つは構成本体を含むテーブルで、名前空間 ID をキーとする。もう 1 つは構成更新の changelog であり、コミットタイムスタンプをキーとする。この構造により、Zanzibar サーバは起動時にすべての構成をロードし、changelog を監視して構成を継続的に更新できる。
3.1.4 Replication
レイテンシを削減するため、Zanzibar データはクライアントの近くに複製される。レプリカは世界中の数十ヶ所に存在し、リージョンあたり複数のレプリカが置かれている。投票レプリカは 5 つあり、米国東部および中央部に位置し、3 つの異なる都市圏に分散して障害を分離しているが、Paxos トランザクションを高速にコミットできるよう互いに 25 ミリ秒以内の距離に配置されている。
3.2 Serving
3.2.1 Evaluation Timestamp
§2.4 で述べた通り、クライアントはリクエスト評価に用いるスナップショットタイムスタンプの下限を保証するために zookie を提供できる。Zookie が提供されない場合、サーバは既定の staleness(鮮度遅延)を用いる。この既定値は、レイテンシに悪影響を与えることなく、あらゆるトランザクションが可能な限り新しいタイムスタンプで評価されるように選ばれる。
Zanzibar が Spanner へ行う各読み取りリクエストでは、そのタイムスタンプでのデータがゾーン外 (out-of-zone) 読み取りを必要としたかどうか、すなわち追加レイテンシを発生させたかどうかのヒントが返される。各サーバは、既定の staleness での out-of-zone 読み取りの頻度と、より新しい・より古いデータでの頻度を追跡し、これらの頻度を用いて、各 staleness において任意のデータがローカルで利用可能である確率の二項割合信頼区間 (binomial proportion confidence interval) を計算する。
十分なデータが集まると、サーバは各 staleness 値について、out-of-zone 読み取りが発生する確率が十分低く、したがって低レイテンシであるかどうかを確認する。もしそうであれば、既定の staleness の上限を、そうした「安全な (safe)」値のうち最も低いものに更新する。既知のどの staleness 値も安全でない場合、我々は two-proportion z-test を用いて、既定値を増やすことで統計的に有意なレベルで安全性が向上するかどうかを確認する。その場合、レイテンシの改善を期待して既定値を増加させる。この既定の staleness メカニズムは純粋に性能最適化であり、zookie が提供された場合には必ずそれを尊重するため、一貫性セマンティクスを損なうことはない。
3.2.2 Config Consistency
名前空間構成の変更は ACL 評価の結果、ひいてはその正しさに影響する可能性があるため、Zanzibar は各クライアントリクエストを評価する際に、構成メタデータに対して単一のスナップショットタイムスタンプを選択する。クラスター内のすべての aclserver は、元のクライアントリクエストからファンアウトするサブリクエストを含め、同じリクエストについて同じタイムスタンプを使用する。
各サーバは、§3.1.3 で述べた通り、構成の変更に合わせてストレージから名前空間構成を継続的にロードする。そのため、再起動やネットワーク遅延により、クラスター内の各サーバが利用できる構成タイムスタンプの範囲は異なる場合がある。Zanzibar は、すべてのサーバで利用可能なタイムスタンプを選ばなければならない。このために、監視ジョブが各サーバで利用可能なタイムスタンプ範囲を追跡して集約し、他のすべてのサーバに対してグローバルに利用可能な範囲を報告する。各受信リクエストに対して、サーバはこの範囲から 1 つの時刻を選択し、構成ストレージから読み取れなくなったサーバがあっても、すべてのサーバが処理を継続できるようにする。
3.2.3 Check Evaluation
Zanzibar は、チェックリクエストをブール式に変換することで ACL チェックを評価する。単純なケース、すなわち userset リライトルールが存在しない場合、ユーザ U を userset ⟨object # relation⟩ に対してチェックすることは、以下のように表現できる:
CHECK(U, ⟨object # relation⟩) =
∃ tuple ⟨object # relation @ U⟩
∨ ∃ tuple ⟨object # relation @ U′⟩, where
U′ = ⟨object′ # relation′⟩ such that CHECK(U, U′).
妥当な U′ = ⟨object′ # relation′⟩ を見つけることは、すべての間接 ACL やグループに対するメンバーシップを再帰的に評価することを意味する。この種の「ポインタ追跡 (pointer chasing)」は、多くのタイプの ACL やグループに対しては有効に機能するが、間接 ACL やグループが深かったり幅広かったりすると高コストになる。§3.2.4 では、この問題をどのように扱っているかを説明する。Userset リライトルールも、チェック評価の一部としてブール式に変換される。
チェックのレイテンシを最小化するため、我々はブール式木のすべての葉ノードを並行に評価する。あるノードの結果によって部分木全体の結果が決定される場合、その部分木内の他のノードの評価はキャンセルされる。
葉ノードの評価には通常、データベースからのリレーションタプルの読み取りが含まれる。我々は、同一の ACL チェックに対する読み取りをまとめるプーリングメカニズムを適用し、Spanner への読み取り RPC の数を最小化している。
3.2.4 Leopard Indexing System
チェック評価中の再帰的ポインタ追跡は、深くネストしていたり、多数の子グループを持つグループに対して、低レイテンシを維持することが難しい。こうした構造を持つ一部の名前空間について、Zanzibar は Leopard を用いてチェックを処理する。Leopard は、集合演算を効率的に行えるように設計された専用インデックスである。
Leopard インデックスは、(T, s, e) タプルを用いて名前付き集合のコレクションを表現する。ここで T は集合タイプを表す enum、s と e はそれぞれ集合 ID と要素 ID を表す 64 ビット整数である。クエリは、名前付き集合の union、intersection、exclusion の式を評価し、指定された結果数の上限まで、要素 ID でソートされた結果集合を返す。
グループメンバーシップをインデックスし評価するため、Zanzibar はグループメンバーシップを 2 つの集合タイプ GROUP2GROUP と MEMBER2GROUP で表す。ここでは、集合 ID から要素 ID への写像として示す:
- GROUP2GROUP(s) → {e}\ ここで s は先祖グループを表し、e は先祖グループの直接または間接のサブグループである子孫グループを表す。
- MEMBER2GROUP(s) → {e}\ ここで s は個々のユーザを表し、e はそのユーザが直接のメンバーである親グループを表す。
ユーザ U がグループ G のメンバーかどうかを評価するには、次を満たすかどうかを確認する:
(MEMBER2GROUP(U) ∩ GROUP2GROUP(G)) ≠ 0
グループメンバーシップは、ノードがグループとユーザ、エッジが直接メンバーシップを表すグラフにおける到達可能性 (reachability) の問題とみなせる。グループ間のパスをフラット化することで、Leopard によって到達可能性を効率的に評価できる。他の種類の非正規化も、データパターンに応じて適用可能である。
Leopard システムは 3 つの独立した部分から構成される。すなわち、集合に対する一貫性のある低レイテンシな操作を実現するサービングシステム、オフラインの定期的なインデックス構築システム、およびタプル変更に応じてサービングシステムを継続的に更新可能なオンラインリアルタイムレイヤーである。
インデックスタプルは、スキップリストなどの構造内で整数の順序付きリストとして保存される。これにより、集合間の union や intersection を効率的に行うことができる。例えば、2 つの集合 A と B の intersection を評価するには、O(min(|A|, |B|)) のスキップリストシークだけが必要となる。インデックスは要素 ID でシャーディングされ、複数サーバに分散可能である。シャードは通常メモリ上のみで提供されるが、メモリとリモートのソリッドステートデバイスにまたがるホットデータとコールドデータの混在構成で提供されることもある。
オフラインインデックスビルダーは、Zanzibar のリレーションタプルおよび構成のスナップショットからインデックスシャードを生成し、それらをグローバルに複製する。この際、userset リライトルールを尊重し、ACL グラフ内のエッジを再帰的に展開して Leopard インデックスタプルを形成する。Leopard サーバは、新しいシャードを継続的に監視し、利用可能になり次第古いシャードと入れ替える。
ここまでの Leopard システムは、深く・幅広くネストしたグループメンバーシップを効率的に評価できるが、オフラインインデックス生成とシャード入れ替えのため、最新かつ一貫したスナップショットで評価することはできない。一貫した ACL 評価をサポートするため、Leopard サーバはオフラインスナップショット以降のすべての更新をインデックスするインクリメンタルレイヤーを維持する。ここで各更新は (T, s, e, t, d) タプルで表され、t は更新のタイムスタンプ、d は削除フラグ (deletion marker) である。クエリ処理中には、クエリタイムスタンプ以下のタイムスタンプを持つ更新がオフラインインデックスにマージされる。
インクリメンタルレイヤーを維持するため、Leopard インクリメンタルインデクサは Zanzibar の Watch API を呼び出し、時間順に並んだ Zanzibar タプル変更ストリームを受信し、それを時間順の Leopard タプルの追加・更新・削除ストリームに変換する。GROUP2GROUP タプルの更新を生成するには、インクリメンタルインデクサがグループ間メンバーシップを保持し、1 つのリレーションタプル更新が複数のインデックス更新に波及しうる非正規化の効果を反映する必要がある。
実際には、単一の Zanzibar タプルの追加または削除が、潜在的には数万件に及ぶ個々の Leopard タプルイベントを生み出す場合もある。各 Leopard サービングインスタンスは、Watch API を通じてこれらの Zanzibar タプル変更の完全なストリームを受信する。Leopard サービングシステムは、このストリームを継続的に取り込み、クエリ処理への影響を最小限に抑えつつ、各種ポスティングリストを更新するよう設計されている。
3.2.5 Handling Hot Spots
ACL の読み取りおよびチェックのワークロードは、バースト的でホットスポットが発生しやすい。例えば、検索クエリに応答するには、候補となる検索結果すべてに対して ACL チェックを行う必要があり、それらの ACL はしばしば共通のグループや間接 ACL を共有している。一貫性を保つため、Zanzibar はストレージの非正規化を避け、正規化されたデータのみに依存している(§3.2.4 で述べた例外を除く)。正規化されたデータでは、共通の ACL(例: 人気のあるグループ)に対するホットスポットが、基盤となるデータベースサーバを過負荷にさせる可能性がある。我々は、低レイテンシと高可用性を追求するうえで、ホットスポットへの対処が最も重要な課題であることを見いだした。
各クラスター内の Zanzibar サーバは、リレーションタプルの読み取りやチェック評価(ポインタ追跡中に評価される中間チェック結果を含む)のための分散キャッシュを形成する。キャッシュエントリは、コンシステントハッシュ [20] によって Zanzibar サーバ間に分散される。チェックや読み取りを処理するため、内部 RPC インタフェースを介して、対応する Zanzibar サーバへのリクエストをファンアウトする。内部 RPC の数を最小化するため、多くの名前空間では、フォワーディングキーを object ID から計算する。これは、⟨object # relation⟩ に対するチェックの処理が、そのオブジェクト上の他のリレーションに対する間接 ACL チェックや、そのオブジェクトのリレーションタプルの読み取りを伴うことが多いためである。これらのチェックや読み取りは、親のチェックリクエストと同じフォワーディングキーを共有するため、同じサーバで処理できる。ホットなフォワーディングキーに対処するため、我々は内部 RPC の呼び出し元と呼び出し先の両方で結果をキャッシュし、事実上キャッシュツリーを形成している。また、Slicer [12] を用いてホットキーを複数サーバへ分散する。
我々は、異なるスナップショットから評価された結果を再利用しないよう、キャッシュキーにスナップショットタイムスタンプをエンコードしている。リクエストの zookie による staleness 制約を尊重しつつ、評価タイムスタンプは 1 秒または 10 秒といった粗い粒度へ切り上げて選択する。このタイムスタンプの量子化 (quantization) により、キャッシュキーにはマイクロ秒精度のタイムスタンプを用いているにもかかわらず、最近のチェックや読み取りの大半が同じタイムスタンプで評価され、キャッシュ結果を共有しやすくなる。タイムスタンプの切り上げによって Zanzibar の一貫性特性が損なわれないことは、Spanner が、タイムスタンプ T におけるスナップショット読み取りが T までのすべての書き込みを観測することを保証している点からも明らかである。これは T が将来の時刻である場合でも同様であり、その場合読み取りは TrueTime が T を超えるまで待機する。
「cache stampede」問題 [3]、すなわち、キャッシュに結果が蓄積される前に同時発生するリクエストがフラッシュホットスポットを生み出してしまう問題に対処するため、我々は各サーバにロックテーブルを保持し、未処理の読み取りやチェックを追跡している。同じキャッシュキーを共有するリクエスト群のうち 1 件だけが処理を開始し、残りはキャッシュが埋まるまでブロックされる。
分散キャッシュとロックテーブルを用いることで、ホットスポットの大半を効果的に処理できるようになった。時間の経過とともに、我々は次の 2 つの改善を行った。
第一に、あるユーザに対する特定オブジェクトとリレーションの直接メンバーシップチェック(すなわち ⟨object # relation @ user⟩)は、通常 1 回のリレーションタプル lookup だけで処理される。しかし、非常に人気のあるオブジェクトでは、多数のユーザに対する同時チェックが発生し、当該オブジェクトのリレーションタプルを保持するストレージサーバがホットスポットとなることがある。こうしたホットスポットを回避するため、我々はホットなオブジェクトについて、⟨object
relation⟩
のすべてのリレーションタプルを読み取り・キャッシュすることで、読み取り帯域幅と引き換えにキャッシュ性を向上させる。どのオブジェクトにこの方法を適用するかは、各オブジェクトに対する未処理読み取りの数を追跡することで、動的にホットオブジェクトを検出して決定する。
第二に、親の ACL チェックの結果がすでに決定されている場合、間接 ACL チェックは頻繁にキャンセルされる。このとき、対応するキャッシュキーは未設定のまま残ってしまう。積極的なキャンセルはリソース使用を大きく削減する一方で、そのロックテーブルエントリにブロックされている同時リクエストのレイテンシには悪影響を与える。こうしたレイテンシの悪化を防ぐため、対応するロックテーブルエントリに待機中のリクエストが存在する場合には、積極的キャンセルを遅延させる。
3.2.6 Performance Isolation
低レイテンシと高可用性を目標とする共有サービスにとって、パフォーマンスの隔離 (performance isolation) は不可欠である。Zanzibar またはそのクライアントのいずれかが、予期せぬ利用パターンに対処するリソースを一時的に十分確保できなかった場合でも、以下の隔離メカニズムによって、パフォーマンス問題は問題のあるユースケースに限定され、他のクライアントに悪影響を及ぼさないようにしている。
第一に、CPU キャパシティの適切な割り当てを保証するため、Zanzibar は各 RPC のコストを汎用的な cpu-seconds というハードウェア非依存の指標で測定する。各クライアントには、1 秒あたりの最大 CPU 使用量に対するグローバルな上限があり、そのクライアントの RPC は、上限を超えており、かつシステム全体に余剰キャパシティがない場合にはスロットルされる。
各 Zanzibar サーバは、メモリ使用量を制御するために、未処理 RPC の総数にも上限を設けている。同様に、クライアントごとの未処理 RPC 数にも上限を設けている。
Zanzibar はさらに、各 Spanner サーバにおいて、(object, client) ごとおよびクライアントごとの同時読み取り数の最大値を制限する。これにより、単一のオブジェクトやクライアントが Spanner サーバを独占できないようにしている。
最後に、クライアントごとに異なるロックテーブルキーを用いることで、Spanner が特定クライアントに適用するスロットリングが、他のクライアントに影響しないようにしている。
3.2.7 Tail Latency Mitigation
Zanzibar の分散処理では、遅いタスクに対処するための対策が必要となる。Spanner および Leopard インデックスへの呼び出しについては、request hedging [16](同一リクエストを複数サーバに送信し、最初に返ってきた応答を使用して他のリクエストをキャンセルする手法)に依存している。往復時間 (RTT) を削減するため、Zanzibar サーバが存在する各地理的リージョンにおいて、これらバックエンドサービスのレプリカを少なくとも 2 つ配置するようにしている。不要に負荷を増やさないため、最初は 1 つのリクエストだけを送信し、そのリクエストが遅いことが判明してからヘッジ用リクエストを送るようにしている。
適切なヘッジ遅延しきい値を決定するため、各サーバは遅延推定器を保持し、最近の測定値に基づいて N パーセンタイルレイテンシを動的に計算する。このメカニズムにより、ヘッジによって追加で発生するトラフィックを総トラフィックのごく一部に抑えることができる。
効果的なヘッジには、リクエストのコストが類似していることが必要となる。Zanzibar の認可チェックの場合、一部のチェックは他のチェックよりも多くの処理を必要とするため、本質的に高コストである。チェックリクエストに対してヘッジを行うと、最も高価なワークロードを複製することになり、皮肉にもレイテンシを悪化させてしまう。そのため、我々は Zanzibar サーバ間のリクエストに対してはヘッジを行わず、前述の複数レプリカへのシャーディングおよび監視メカニズムに依存して遅いサーバを検出・回避している。
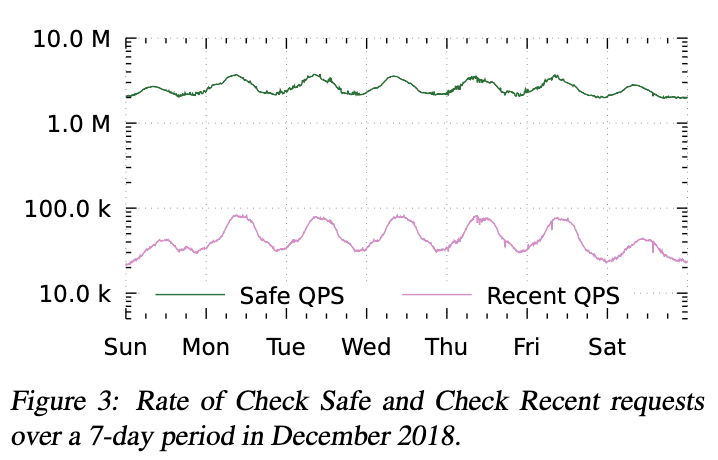
Figure 3: Rate of Check Safe and Check Recent requests over a 7-day period in December 2018.
4 Experience
Zanzibar は本番環境で 5 年以上運用されている。その間ずっと、Zanzibar を利用するクライアントの数と、クライアントが Zanzibar に与える負荷は、着実に増加してきた。この章では、グローバルに分散された認可システムとして Zanzibar を運用してきた経験について述べる。
Zanzibar は、数百に及ぶクライアントアプリケーションによって定義された 1,500 以上の名前空間を管理している。名前空間構成ファイルのサイズは、その名前空間で実装されているアクセス制御ポリシーの複雑さをおおまかに測る指標となる。これらの構成ファイルの行数は、数十行から数千行まで幅広く分布しており、中央値は約 500 行である。
これらの名前空間には、2 兆を超えるリレーションタプルが含まれており、合計でほぼ 100 テラバイトを占めている。名前空間ごとのタプル数は、数十から 1 兆まで何桁にもわたって分布しており、その中央値は約 15,000 である。このデータは、ユーザへの近接性と高可用性の両方を維持するため、世界中の 30 箇所以上で完全に複製されている。
Zanzibar は、毎秒 1000 万件を超えるクライアントクエリ (QPS) を処理する。2018 年 12 月の 7 日間のサンプル期間では、Check リクエストはおよそ 420 万 QPS、Read は 820 万 QPS、Expand は 76 万 QPS、Write は 2.5 万 QPS でピークに達している。データを読み取るクエリは、データを書き込むクエリより 2 桁多く発生している。
Zanzibar は、この負荷を、世界中にある数十のクラスターにまたがる 1 万台以上のサーバに分散している。クラスターあたりのサーバ台数は、100 台未満から 1,000 台超まで幅があり、中央値はおよそ 500 台である。クラスターのサイズは、地理的地域ごとの負荷に比例して決定される。
4.1 Requests
我々は、要求されるデータの新しさ (freshness) に基づき、リクエストを 2 つのカテゴリに分けている。データの新しさは、リクエストのレイテンシと可用性に大きな影響を与える可能性があるためである。具体的には、Check、Read、Expand リクエストは、評価タイムスタンプの下限を指定するための zookie を持つことができる。Zookie のタイムスタンプが、そのリージョンに複製された最新データのタイムスタンプより新しい場合、ストレージの読み取りは、より新しいデータを取得するために、リーダレプリカへのリージョン間ラウンドトリップを必要とする。我々のストレージは 8 秒間隔のレプリケーションハートビートで構成されているため、リクエストを次の 2 つのカテゴリに分けている。Safe リクエストは zookie が 10 秒以上前のものであり、ほとんどの場合リージョン内で処理できる。一方、Recent リクエストは zookie が 10 秒未満前のものであり、しばしばリージョン間ラウンドトリップを必要とする。我々は両者を別々に統計計測している。
Figure 3 は、7 日間における Check Safe リクエストと Check Recent リクエストのレートを示している。どちらも日周サイクルを示している。Safe リクエストのレートは Recent リクエストよりおよそ 2 桁大きく、そのおかげで Zanzibar は ACL チェックの大部分をローカルで処理できている。
4.2 Latency
Zanzibar のレイテンシ予算は、Zanzibar を利用するクライアントが対話的サービスとして成立するために必要な、数百ミリ秒程度の総応答時間のうち、ごく一部に過ぎない。例えば、クライアントが複数のドキュメントに対して認可チェックを行ってから、それらのドキュメントに対する検索結果をユーザに表示するような場合を考えてみよう。
我々は、レイテンシをサーバサイドで、実際のトラフィックを用いて測定している。その理由は (1) レイテンシはキャッシュや重複排除メカニズムの影響を強く受け、それらは実トラフィックを用いた場合にのみ現実的に反映されること、そして (2) クライアント側でレイテンシを正確に測定するためには、クライアントが適切に動作している必要があるが、クライアントジョブのプロビジョニングは Zanzibar の管理外であり、ときどきクライアントジョブが過負荷になることがあるためである。
Figure 4 は、7 日間における Check Safe 応答のレイテンシを示している。50 パーセンタイル、95 パーセンタイル、99 パーセンタイル、99.9 パーセンタイルで、それぞれおよそ 3 ms、11 ms、20 ms、93 ms にピークを持つ。この性能は、ユーザとの対話のクリティカルパスに頻繁に現れる処理に対する我々のレイテンシ目標を満たしている。
表 2 は、同じ 7 日間における Check、Read、Expand、Write 応答のレイテンシ分布をまとめたものである。意図した通り、より頻繁に利用される Safe バージョンの Check、Read、Expand は、利用頻度の低い Recent バージョンよりも有意に高速である。Writes はすべての API の中で最も利用頻度が低く、また常に Spanner サーバ間の分散調整を必要とするため、最も遅い。
Table 2: Mean and standard deviation of RPC response latency over a 7-day period in December 2018.
| Latency in milliseconds, µ ( σ ) | Latency in milliseconds, µ ( σ ) | Latency in milliseconds, µ ( σ ) | |
|---|---|---|---|
| API | 50%ile | 95%ile | 99%ile |
| Check | 3 . 0 ( 0 . 091 ) | 9 . 46 ( 0 . 3 ) | 15 . 0 ( 1 . 19 ) |
| Read | 2 . 18 ( 0 . 031 ) | 3 . 71 ( 0 . 094 ) | 8 . 03 ( 3 . 28 ) |
| Expand | 4 . 27 ( 0 . 313 ) | 8 . 84 ( 0 . 586 ) | 34 . 1 ( 4 . 35 ) |
| Check | 2 . 86 ( 0 . 087 ) | 60 . 0 ( 2 . 1 ) | 76 . 3 ( 2 . 59 ) |
| Read | 2 . 21 ( 0 . 054 ) | 40 . 1 ( 2 . 03 ) | 86 . 2 ( 3 . 84 ) |
| Expand | 5 . 79 ( 0 . 224 ) | 45 . 6 ( 3 . 44 ) | 121 . 0 ( 2 . 38 ) |
| Write | 127 . 0 ( 3 . 65 ) | 233 . 0 ( 23 . 0 ) | 401 . 0 ( 133 . 0 ) |
4.3 Availability
我々は、サービスがレイテンシしきい値以内に正常に応答した「適格な (qualified)」RPC の割合を可用性として定義している。Safe リクエストのレイテンシしきい値は 5 秒、Recent リクエストは Spanner のリーダ再選出に最大 10 秒かかる可能性があるため 15 秒である。RPC が適格であるためには、リクエストが正しく構成されており、かつリクエストの deadline がレイテンシしきい値より長くなければならない。さらに、クライアントが自身のリソースクォータの範囲内におさまっている必要がある。
これらの理由から、我々は可用性を実トラフィックだけから直接測定することはできない。クライアントが短い deadline で RPC を送信したり、進行中の RPC をキャンセルしたりすることがあるためである。その代わりに、実トラフィックから有効なリクエストのごく一部をサンプリングし、それらを後で我々自身のプローバー (prober) を使って再生する。再生時には、タイムアウトを可用性しきい値より長く設定する。また、リクエストに zookie が指定されている場合、その zookie を調整し、再生時の zookie の相対的な古さが、実トラフィックで受信したときと同じになるようにする。最後に、クラスターごとに 3 つの prober を実行し、まれな prober 障害による誤検知を排除するため、外れ値を除外する。
可用性を計算するために、我々はクラスターごとの成功率を集約し、90 日間のウィンドウで平均する。Figure 5 は、プローバーによって計測された Zanzibar の可用性を示している。Google での運用において、過去 3 年間、可用性は 99.999% を上回り続けている。言い換えれば、四半期ごとに、Zanzibar の全世界的なダウンタイムは 2 分未満であり、グローバルなエラー比率が 10% を超える時間は 13 分未満である。
4.4 Internals
Zanzibar サーバは、コンシステントハッシュに基づいて互いにチェックや読み取りを委譲 (delegate) し、委譲された処理の呼び出し側と受け側の両方で結果をキャッシュすることで、ホットスポットを防いでいる (§3.2.5)。ピーク時には、Zanzibar は 1 秒あたり 2,200 万件の内部「委譲」RPC を処理しており、その約半分が読み取り、残り半分がチェックである。インメモリキャッシュはピーク時に 1 秒あたり約 2 億件の lookup を処理しており、そのうち 1 億 5,000 万件がチェック、5,000 万件が読み取りに由来する。チェック向けキャッシュは、委譲先側のキャッシュで 10% のヒット率を持ち、さらにロックテーブルによって 12% が節約されている。一方、委譲元側キャッシュのヒット率は 2% であり、ロックテーブルによってさらに 3% が節約されている。一見するとヒット率は低いように見えるが、これらによって 1 秒あたり 50 万件の内部 RPC が発生せずに済み、ホットスポットの発生を防いでいる。
委譲された読み取りでは、委譲先側でより高いヒット率が得られており、キャッシュで 24%、ロックテーブルで 9% である。一方、委譲元側キャッシュのヒット率は 1% 未満である。極端にホットなグループに対して、Zanzibar はさらに最適化を行い、事前に全メンバー集合を読み取り・キャッシュする。この処理は全グループの 0.1% に対してのみ行われるが、ホットスポットをさらに防いでいる。
このキャッシングと、読み取りリクエストの積極的なプーリングによって、Zanzibar が Spanner に発行する読み取り RPC は 1 秒あたり 2,000 万件に抑えられている。これらリクエストの中央値では、1 RPC あたり 1.5 行を読み取っているが、99 パーセンタイルでは 1 RPC あたり約 1,000 行を読み取っている。
Zanzibar の Spanner 読み取りは、中央値で 0.5 ms、95 パーセンタイルで 2 ms である。我々は、Spanner 読み取りの 1%、すなわち 1 秒あたり 20 万件がヘッジングの恩恵を受けていることを確認している。なお、Zanzibar が使用している Spanner インスタンスは Google 内部で動作するものであり、Cloud Spanner [6] のインスタンスではない。
Leopard インデックスは、7 日間の集計データに基づくと、中央値で 1.56M QPS、99 パーセンタイルで 2.22M QPS を処理している。同じ 7 日間において、Leopard サーバは、中央値で 150 マイクロ秒未満、99 パーセンタイルでも 1 ms 未満で応答している。Leopard のインクリメンタルレイヤーは、その 7 日間において、中央値で毎秒およそ 500 件、99 パーセンタイルで毎秒およそ 1.5K 件のインデックス更新を書き込んでいる。
4.5 Lessons Learned
Zanzibar は、Google Calendar、Google Cloud、Google Drive、Google Maps、Google Photos、YouTube など、増え続けるクライアント群に対する多様かつ重い要求を満たすべく進化してきた。この節では、その経験から得られた教訓を強調する。
共通したテーマの 1 つは、クライアント間の違いに対応するための柔軟性の重要性である。例えば:
- アクセス制御パターンはクライアントによって大きく異なる: 時間の経過とともに、我々は特定のクライアントをサポートするための機能を追加してきた。例えば、
- 我々は computed userset を追加し、オブジェクト ID のプレフィックスからオブジェクトの owner ID を推論できるようにした。これは、多数のプライベートオブジェクトを管理する Drive や Photos といったクライアントにとって、必要な空間量を削減する効果がある。同様に、tuple to userset を追加することで、オブジェクト階層をホップごとに 1 つのリレーションタプルだけで表現できるようにした。その利点は、空間削減だけでなく柔軟性にもある。Cloud のようなクライアントは、ACL 継承をコンパクトに表現しつつ、大量のタプルを更新することなく ACL 継承ルールを変更できる。§2.3.1 を参照。
- Freshness 要件は、多くの場合ゆるいが、常にそうとは限らない: クライアントは、ACL 評価中の staleness について、未指定の中程度の staleness を許容することが多い一方で、ときにはより厳密に指定された freshness を必要とする場合もある。我々はこの性質を踏まえて zookie プロトコルを設計し、大半のリクエストは既定の、すでに複製済みのスナップショットから処理しつつ、必要に応じてクライアントが staleness に上限を設定できるようにした。また、スナップショットタイムスタンプの粒度を、クライアントの freshness 要件に合うように調整した。その結果としての粗いタイムスタンプ単位によって、我々は大半の認可チェックを少数のスナップショット上で実行できるようになり、データベース読み取りの頻度を大きく削減できている。§3.2.1 を参照。
別のテーマは、本番環境で観測されたクライアントの振る舞いを支えるために、性能最適化を追加する必要性である。例えば:
- Request hedging はテイルレイテンシ削減の鍵である: Drive のように検索機能をユーザに提供するクライアントは、単一の検索結果集合を返すために、しばしば数十から数百の認可チェックを発行する。我々は、Spanner および Leopard へのリクエストに対してヘッジングを導入し、一部の処理が遅くても、全体的なユーザ操作が遅くならないようにした。§3.2.7 を参照。
- ホットスポット緩和は高可用性のために極めて重要である: 一部のワークロードは ACL データにホットスポットを生み出し、基盤となるデータベースサーバを過負荷にする可能性がある。よく見られるパターンは、多くの異なるオブジェクトの ACL が、間接的に同じオブジェクトを参照している場合、そのオブジェクトに対する ACL チェックが一気に集中するようなバーストである。具体例としては前述の検索ユースケースがあり、検索結果に含まれるドキュメント群が、大きなソーシャルまたは職場グループに対する ACL を間接的に共有しているケースや、Cloud のユースケースで、多数のオブジェクトが階層の高い 1 つのオブジェクトに対する ACL を間接的に共有しているケースなどが挙げられる。Zanzibar は分散キャッシュやロックテーブルなどの一般的なメカニズムを用いて、ホットスポットの大半に対処しているが、特定のユースケースに対してはさらなる最適化が必要になることも分かった。例えば、ホットオブジェクトに対しては、その ⟨object # relation⟩ に属するすべてのリレーションタプルをキャッシュに事前取得する機能を追加した。また、同じ ACL データに対する並行リクエストが存在する場合、二次的な ACL チェックのキャンセルを遅延させるようにした。§3.2.5 を参照。
- 誤動作するクライアントから守るためのパフォーマンス隔離は不可欠である: ホットスポット緩和策を講じていても、予期しない、あるいは意図しないクライアントの振る舞いによって、我々のシステムや基盤インフラが過負荷になる可能性は残る。例えば、クライアントが新しい機能をローンチしたところ予想外に人気が出た場合や、Zanzibar を想定外の方法で利用した場合などである。我々は時間とともに、クライアント間や同一クライアント内のオブジェクト間で連鎖的な障害が発生しないよう、隔離のための安全策を追加してきた。これらの安全策には、細粒度のコスト計測、クォータ、スロットリングなどが含まれる。§3.2.6 を参照。
5 Related Work
Zanzibar は、惑星規模 (planet-scale) の分散 ACL ストレージ兼評価システムである。その認可の概念の多くは、アクセス制御やソーシャルグラフの分野において以前から研究されてきたものであり、そのスケーリングに関する課題も分散システムの分野で調査されてきた。
アクセス制御はマルチユーザオペレーティングシステムの中核をなす要素である。Multics [23] はセグメントとディレクトリに対する ACL をサポートしている。ACL エントリはプリンシパル識別子とパーミッションビットの集合から構成される。UNIX 第 1 版 [9] では、ファイルフラグは所有者と非所有者がファイルを読み書きできるかどうかを示す。第 4 版までには、パーミッションビットはオーナ、グループ、その他に対する読み/書き/実行ビットへと拡張された。POSIX ACL [4] は、最大 32 個のパーミッションビットを持つ任意のユーザとグループのリストを追加する。VMS [7, 8] は、ディレクトリツリー内で作成されたファイルに対する ACL 継承をサポートしている。Zanzibar のデータモデルは、上記のシステムに見られるパーミッション、ユーザ、グループ、継承をサポートしている。
Taos [24, 10] は、アイデンティティが分散システムを通過する過程でどのように変換されたかを取り込んだ複合プリンシパル (compound principals) をサポートしている。例えば、ユーザ U がワークステーション W にログインしてファイルサーバ S にアクセスした場合、S は単に U ではなく「W for U」として認証されたリクエストを見る。このことにより、ユーザのメールに対する ACL を「ユーザ本人からのアクセスのみ、かつメールサーバ経由でアクセスされた場合のみ許可」といった形で記述することができる。Abadi らは [11] において、複合アイデンティティをサポートするグループベース ACL モデルについて議論している。彼らの「blessings」の概念は Zanzibar のタプルと似ている。しかし、Zanzibar は ACL とグループに対して userset を用いた統一的な表現を採用しているのに対し、[11] ではそれらは別個の概念である。
ロールベースアクセス制御 (RBAC) は [17] で初めて提案され、Zanzibar の relation に類似した role の概念を導入した。ロールは互いに継承可能であり、パーミッションを意味する。多くの Zanzibar クライアントは、Zanzibar の名前空間構成言語の上に RBAC ポリシーを実装している。
2019 年に ACL ストアについて議論するのであれば、Amazon [1]、Google [5]、Microsoft [2] などが商用で提供している Identity and Access Management (IAM) システムに触れずには済まされない。これらのシステムは、それぞれのクラウド製品の顧客に対し、次のような機能に基づいて柔軟なアクセス制御を構成することを可能にしている: ユーザをロールやグループに割り当てること、ドメイン固有のポリシー言語、ACL の作成や変更を可能にする API など。これらすべてのシステムに共通しているのは、統一された ACL ストレージと RPC ベースの API を備えている点であり、これは Zanzibar の設計哲学の中核でもある。Google の Cloud IAM システム [5] は、Zanzibar の ACL ストレージおよび評価システムの上にレイヤとして構築されている。
TAO [13] は、Facebook のソーシャルグラフ向けの分散データストアである。いくつかの Zanzibar クライアントは、ソーシャルグラフの保存にも Zanzibar を利用している。Zanzibar と TAO はともにクライアントに対して認可チェックを提供する。どちらも単一インスタンスサービスとしてデプロイされ、大規模スケールで動作し、読み取り専用操作に最適化されている。TAO は、非同期レプリケーションによる最終的 (eventual) なグローバル一貫性と、同期的なキャッシュ更新によるベストエフォートの read-after-write 一貫性を提供する。対照的に、Zanzibar は external consistency と bounded staleness を持つスナップショット読み取りを提供し、ACL とコンテンツ更新の間の因果順序を尊重することで、「new enemy」問題から保護する。
Lamport clocks [22] は、イベントの順序を決定するために利用できる、部分順序付きベクタタイムスタンプを提供する。しかし、Lamport clocks では、すべての「プロセス」が明示的に参加する必要がある。一方で、Zanzibar のユースケースでは、一部の「プロセス」は外部クライアントや、さらには人間のユーザである可能性がある。これに対し、Zanzibar は基盤となるデータベースシステムである Spanner [15] に依存して、external consistency と bounded staleness を持つスナップショット読み取りの両方を提供している。特に、Zanzibar は Spanner の TrueTime 抽象 [15] の上に構築されており、zookie としてエンコードされる線形化可能なコミットタイムスタンプを提供している。
同時に、Zanzibar は Spanner が提供する機能の上に、いくつかの追加機能を実装している。1 つには、zookie プロトコルはクライアントが任意のスナップショットで ACL を読み取ったり評価したりすることを許さない。この制約により、Zanzibar は ACL 評価を高速に行えるスナップショットを選択できる。また、Zanzibar はデータベースのホットスポット(例えば、突然人気になった動画に対する認可チェック)や、深い再帰が発生しうるにもかかわらず安全なポインタ追跡(例えば、階層化されたグループに対するメンバーシップチェック)もサポートしている。
Chubby 分散ロックサービス [14] は信頼性の高いストレージを提供し、書き込みを直列化し、アクセス制御も提供するが、Zanzibar のユースケースをサポートするために必要な機能は備えていない。特に、Chubby は大量のデータ、効率的なレンジ読み取り、クライアントが指定したスナップショットでの bounded staleness 読み取りをサポートしていない。そのキャッシュ無効化メカニズムも、書き込みスループットを制限している。
最後に、ZooKeeper は高性能な調整サービス [19] を提供するが、やはり Zanzibar に必要な機能を欠いている。Chubby と比較すると、より緩やかなキャッシュ一貫性のもとで、より高い読み書きレートを処理できる。しかし、ノード間の更新に対する external consistency を提供しておらず、その linearizability はノードごとの単位でしか保証されない。また、bounded staleness を持つスナップショット読み取りも提供していない。
6 Conclusion
Zanzibar 認可システムは、Google におけるアクセス制御データとロジックを統一するものである。そのシンプルでありながら柔軟なデータモデルと構成言語は、コンシューマアプリケーションとエンタープライズアプリケーションの両方からの、さまざまなアクセス制御ポリシーをサポートしている。
Zanzibar の external consistency モデルは、その最も顕著な特徴の 1 つである。これはユーザ操作の順序を尊重しつつ、グローバルな同期なしに、分散された場所で認可チェックを評価することを可能にする。
Zanzibar は、スケーラビリティ、低レイテンシ、高可用性を提供するために、その他の重要な手法も採用している。例えば、Leopard という、スナップショット一貫性を保ちながら集合演算を効率的に計算するための専用インデックスを用いて、深くまたは広くネストしたグループメンバーシップを評価している。また別の例として、分散キャッシュと、進行中のリクエストを重複排除するメカニズムを組み合わせている。これにより、正規化された一貫したストレージの上でデータを提供する際の重要な本番課題であるホットスポットを緩和している。これらの対策を組み合わせることで、Zanzibar は数兆規模のアクセス制御ルールと、毎秒数百万件の認可リクエストにスケールするシステムとなっている。
7 Acknowledgments
Zanzibar には、多くの人々が技術的な貢献をしてきた。我々は、Dan Barella、Miles Chaston、Daria Jung、Alex Mendes da Costa、Xin Pan、Scott Smith、Matthew Steffen、Riva Tropp、Yuliya Zabiyaka を含む、開発チームの過去および最近のメンバーに感謝する。また、Randall Bosetti、Hannes Eder、Robert Geisberger、Tom Li、Massimo Maggi、Igor Oks、Aaron Peterson、Andrea Yu を含む、サイト信頼性エンジニアリング (Site Reliability Engineering) チームの過去および現在のメンバーにも感謝する。
さらに、多くの人々が本論文の改善に貢献してくれた。David Bacon、Carolin G¨athke、Brad Krueger、Ari Shamash、Kai Shen、Lawrence You からは有益なコメントを受けた。我々はまた、Nadav Eiron と Royal Hansen の支援にも感謝する。最後に、匿名の査読者とシェパードである Eric Eide にも、その建設的なフィードバックに対して感謝したい。
References
- [1] Amazon Web Services Identity and Access Management. https://aws.amazon.com/iam/ . Accessed: 2019-04-16.
- [2] Azure Identity and Access Management. https: //www.microsoft.com/en-us/cloud-platform/ identity-management . Accessed: 2019-04-16.
- [3] Cache stampede. https://en.wikipedia.org/ wiki/Cache_stampede . Accessed: 2019-04-16.
- [4] DCE1.1: Authentication and Security Services. http: //pubs.opengroup.org/onlinepubs/9668899 . Accessed: 2019-04-16.
- [5] Google Cloud Identity and Access Management. https://cloud.google.com/iam/ . Accessed: 2019-04-16.
- [6] Google Cloud Spanner. https://cloud.google. com/spanner/ . Accessed: 2019-04-16.
- [7] HP OpenVMS System Management Utilities Reference Manual. https://support.hpe.com/hpsc/ doc/public/display?docId=emr_na-c04622366 . Accessed: 2019-04-16.
- [8] OpenVMS Guide to System Security. http: //www.itec.suny.edu/scsys/vms/ovmsdoc073/ V73/6346/6346pro_006.html#acl_details . Accessed: 2019-04-16.
- [9] Unix Manual. https://www.bell-labs.com/usr/ dmr/www/pdfs/man22.pdf . Accessed: 2019-04-16.
- [10] ABADI, M., BURROWS, M., LAMPSON, B., AND PLOTKIN, G. A calculus for access control in distributed systems. ACMTrans. Program. Lang. Syst. 15 , 4 (Sept. 1993), 706-734.
- [11] ABADI, M., BURROWS, M., PUCHA, H., SADOVSKY, A., SHANKAR, A., AND TALY, A. Distributed authorization with distributed grammars. In Essays Dedicated to Pierpaolo Degano on Programming Languages with Applications to Biology and Security -Volume 9465 (New York, NY, USA, 2015), SpringerVerlag New York, Inc., pp. 10-26.
- [12] ADYA, A., MYERS, D., HOWELL, J., ELSON, J., MEEK, C., KHEMANI, V., FULGER, S., GU, P., BHUVANAGIRI, L., HUNTER, J., PEON, R., KAI, L., SHRAER, A., MERCHANT, A., AND LEV-ARI, K. Slicer: Auto-sharding for datacenter applications. In 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16) (Savannah, GA, 2016), USENIX Association, pp. 739-753.
- [13] BRONSON, N., AMSDEN, Z., CABRERA, G., CHAKKA, P., DIMOV, P., DING, H., FERRIS, J., GIARDULLO, A., KULKARNI, S., LI, H., MARCHUKOV, M., PETROV, D., PUZAR, L., SONG, Y. J., AND VENKATARAMANI, V. TAO: Facebook's distributed data store for the social graph. In Proceedings of the 2013 USENIX Annual Technical Conference (2013), USENIX ATC '13, pp. 49-60.
-
[14] BURROWS, M. The Chubby lock service for looselycoupled distributed systems. In Proceedings of the
-
7th Symposium on Operating Systems Design and Implementation (Berkeley, CA, USA, 2006), OSDI '06, USENIX Association, pp. 335-350.
- [15] CORBETT, J. C., DEAN, J., EPSTEIN, M., FIKES, A., FROST, C., FURMAN, J. J., GHEMAWAT, S., GUBAREV, A., HEISER, C., HOCHSCHILD, P., HSIEH, W., KANTHAK, S., KOGAN, E., LI, H., LLOYD, A., MELNIK, S., MWAURA, D., NAGLE, D., QUINLAN, S., RAO, R., ROLIG, L., SAITO, Y., SZYMANIAK, M., TAYLOR, C., WANG, R., AND WOODFORD, D. Spanner: Google's globally-distributed database. In Proceedings of the 10th USENIX Conference on Operating Systems Design and Implementation (2012), OSDI '12, pp. 251-264.
- [16] DEAN, J., AND BARROSO, L. A. The tail at scale. Communications of the ACM 56 , 2 (Feb. 2013), 74-80.
- [17] FERRAIOLO, D., AND KUHN, R. Role-based access control. In In 15th NIST-NCSC National Computer Security Conference (1992), pp. 554-563.
- [18] GIFFORD, D. K. Information Storage in a Decentralized Computer System . PhD thesis, Stanford, CA, USA, 1981. AAI8124072.
- [19] HUNT, P., KONAR, M., JUNQUEIRA, F. P., AND REED, B. Zookeeper: Wait-free coordination for internet-scale systems. In Proceedings of the 2010 USENIX Annual Technical Conference (Berkeley, CA, USA, 2010), USENIX ATC '10, USENIX Association.
- [20] KARGER, D., LEHMAN, E., LEIGHTON, T., PANIGRAHY, R., LEVINE, M., AND LEWIN, D. Consistent hashing and random trees: Distributed caching protocols for relieving hot spots on the world wide web. In Proceedings of the Twenty-ninth Annual ACM Symposium on Theory of Computing (New York, NY, USA, 1997), STOC '97, ACM, pp. 654-663.
- [21] KUNG, H. T., AND ROBINSON, J. T. On optimistic methods for concurrency control. ACM Trans. Database Syst. 6 , 2 (June 1981), 213-226.
- [22] LAMPORT, L. Time, clocks, and the ordering of events in a distributed system. Commun. ACM 21 , 7 (July 1978), 558-565.
- [23] SALTZER, J. H. Protection and control of information sharing in Multics. In Proceedings of the Fourth ACM Symposium on Operating System Principles (New York, NY, USA, 1973), SOSP '73, ACM.
- [24] WOBBER, E., ABADI, M., BURROWS, M., AND LAMPSON, B. Authentication in the Taos operating system. In Proceedings of the Fourteenth ACM Symposium on Operating Systems Principles (New York, NY, USA, 1993), SOSP '93, ACM, pp. 256-269.